📝 Paper Summary
Reinforcement Learning for Reasoning
Reward Engineering
HERO improves math reasoning by combining brittle binary verifiers with dense reward models using stratified normalization to preserve correctness semantics and variance-aware weighting to emphasize hard prompts.
Core Problem
Verifiable rewards (0/1) are brittle and sparse, often failing to credit partially correct answers or alternative formats, while continuous reward models provide dense signals that are noisy and easily misaligned.
Why it matters:
- Binary verifiers produce 'all-or-nothing' supervision, causing gradient sparsity when all generated responses in a group fail (all 0s)
- Hard-to-verify tasks (e.g., complex formats) suffer from false negatives where valid solutions are rejected by rigid rule-based checkers
- Pure reward models drift from strict correctness constraints, optimizing for high scores that do not correspond to verifiably correct answers
Concrete Example:
In a hard-to-verify math problem, a model might generate a correct reasoning chain but fail the exact string match due to formatting (e.g., list vs. set). A binary verifier assigns 0 reward, treating it identical to a hallucination. HERO uses the reward model to assign a higher score to the formatting error than the hallucination, enabling learning despite the false negative.
Key Novelty
Hybrid Ensemble Reward Optimization (HERO)
- Stratified Normalization: Bounds continuous reward model scores within intervals defined by the binary verifier (e.g., all verifier-rejected answers are normalized to [0, 0.4], all accepted to [0.6, 1.0]), preserving strict correctness rankings while allowing dense differentiation within groups.
- Variance-Aware Weighting: Dynamically scales the training loss for each prompt based on the variance of reward model scores; high variance implies the prompt is challenging/discriminative and receives higher weight, while trivial prompts are down-weighted.
Architecture
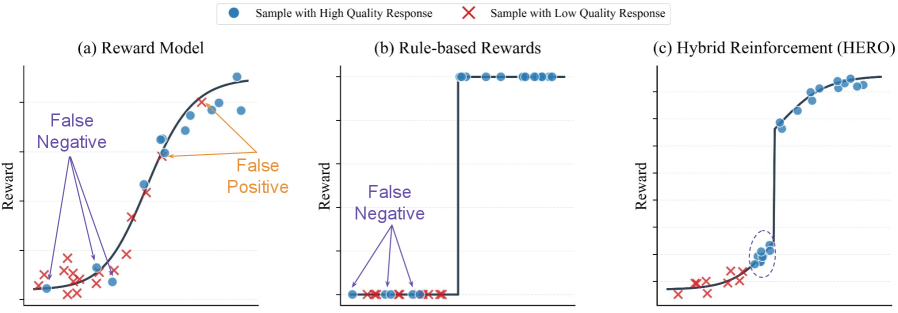
Conceptual comparison of reward landscapes: (a) Noisy Reward Model, (b) Sparse Verifier, and (c) HERO Hybrid Reward.
Evaluation Highlights
- Achieves 66.3% accuracy on hard-to-verify math tasks with Qwen-4B-Base, outperforming the reward-model-only baseline (54.6%) by +11.7 points.
- Surpasses the verifier-only baseline (57.1%) by +9.2 points on the same hard-to-verify benchmark using Qwen-4B-Base.
- Demonstrates consistent gains across easy, hard, and mixed difficulty regimes compared to pure RLVR (Reinforcement Learning with Verifiable Rewards) and RM-only approaches.
Breakthrough Assessment
8/10
Addresses the fundamental 'sparsity vs. noise' trade-off in reasoning RL with a theoretically grounded normalization scheme. Significant empirical gains on hard-to-verify tasks make it a strong contribution to post-training.