📝 Paper Summary
LLM Reasoning
Test-time Scaling
Tree Search Algorithms
STILL-1 improves LLM mathematical reasoning by integrating a policy model with a reward-guided tree search algorithm that explores diverse solution paths and refines strategies via iterative mutual improvement.
Core Problem
LLMs struggle with complex reasoning tasks like STEM problems because they typically generate tokens sequentially without exploring alternative paths or correcting intermediate errors.
Why it matters:
- Standard LLMs lack the 'System 2' slow thinking capability required for multi-step logic, often failing on Olympiad-level math despite high general proficiency.
- Reproducing o1-like reasoning capabilities is challenging due to undisclosed technical details regarding search integration and reward guidance.
- Existing methods often lack a comprehensive framework that unifies policy optimization, robust reward modeling, and effective search algorithms.
Concrete Example:
In a multi-step math problem, a standard LLM might make a calculation error in step 2 and propagate it to the end. The proposed framework uses a tree search to detect low reward scores at that node, backtrack, and explore a correct alternative path.
Key Novelty
STILL-1 (Slow Thinking with LLMs)
- Implements a modular framework combining a policy model adapted for node-based reasoning, a generative reward model for scoring, and an MCTS-based search algorithm.
- Introduces a mutual iterative refinement process where the policy model generates data to train the reward model, which in turn guides the policy's preference optimization.
- Enhances MCTS with a global selection strategy (MCTSG) that considers all leaf nodes rather than just local children, preventing the search from getting stuck in suboptimal local paths.
Architecture
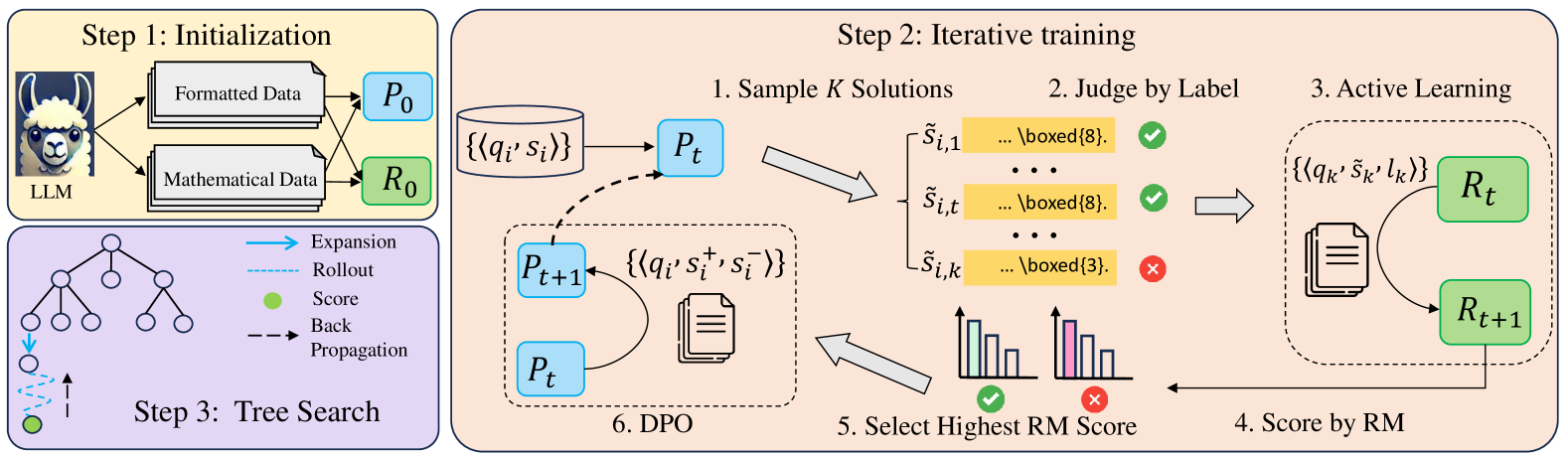
The conceptual framework of STILL-1 comprising Policy Model, Reward Model, and Search Algorithm.
Evaluation Highlights
- Significantly enhances performance on MATH-OAI, GSM-Hard, Olympiad Bench, and College Math compared to the base policy model.
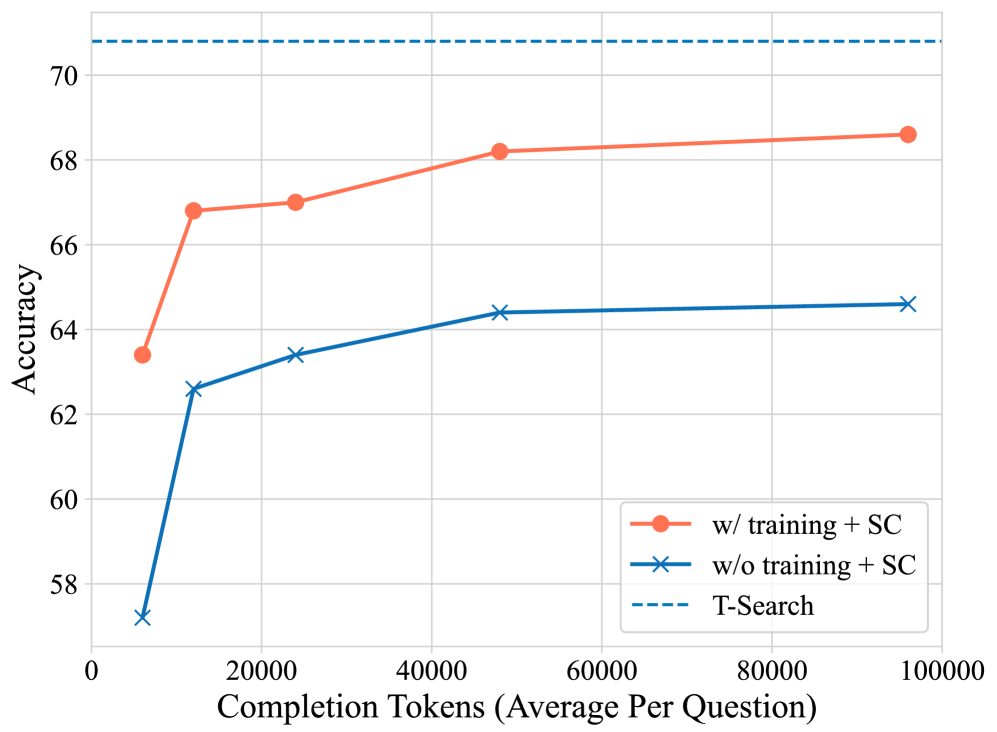
- Demonstrates that the reward-guided search effectively trades test-time compute for higher accuracy on complex reasoning tasks.
- Ablation studies confirm the effectiveness of the global selection strategy (MCTSG) over standard MCTS and Beam Search in difficult scenarios.
Breakthrough Assessment
7/10
Provides a valuable, transparent reproduction study of o1-like reasoning mechanisms with detailed technical explorations of MCTS, reward modeling, and iterative training, though it primarily combines existing techniques rather than inventing fundamentally new ones.