📝 Paper Summary
Self-Correction
Reinforcement Learning (RL)
Post-training
Reflect, Retry, Reward improves LLM performance on verifiable tasks by using Group Relative Policy Optimization (GRPO) to train models to generate effective self-reflections upon failure, rewarding only the reflection tokens that lead to a successful retry.
Core Problem
LLMs often fail at verifiable tasks (math, coding) and standard self-reflection prompts are static and often ineffective, while fine-tuning is impossible without specific failure-correction datasets.
Why it matters:
- Models have blind spots where they fail despite having the necessary knowledge, and simply retrying without better guidance yields diminishing returns
- Generating synthetic training data is impossible if even state-of-the-art models fail the task
- Existing self-correction methods rely on high-quality prompts or external teachers, which do not scale or adapt to specific model weaknesses
Concrete Example:
In the Countdown math game, a model might fail to reach a target number using a list of integers. A standard retry might repeat the same error. The proposed method prompts the model to reflect ('I used the wrong operation order'), and if this reflection leads to a correct equation in the next attempt, the system reinforces the generation of that specific reflection.
Key Novelty
Reflection-Targeted Reinforcement Learning (Reflect, Retry, Reward)
- Treats self-reflection as a learnable policy rather than a fixed prompt: the model learns *how* to reflect on its own mistakes
- Applies rewards strictly to the 'reflection' tokens (masking the answer tokens) via GRPO, ensuring the model optimizes the reasoning process that fixes errors rather than just memorizing answers
- Utilizes a 'Dataset of Failures' for training, bootstrapping improvement solely from binary success/failure signals without human annotations or teacher models
Architecture
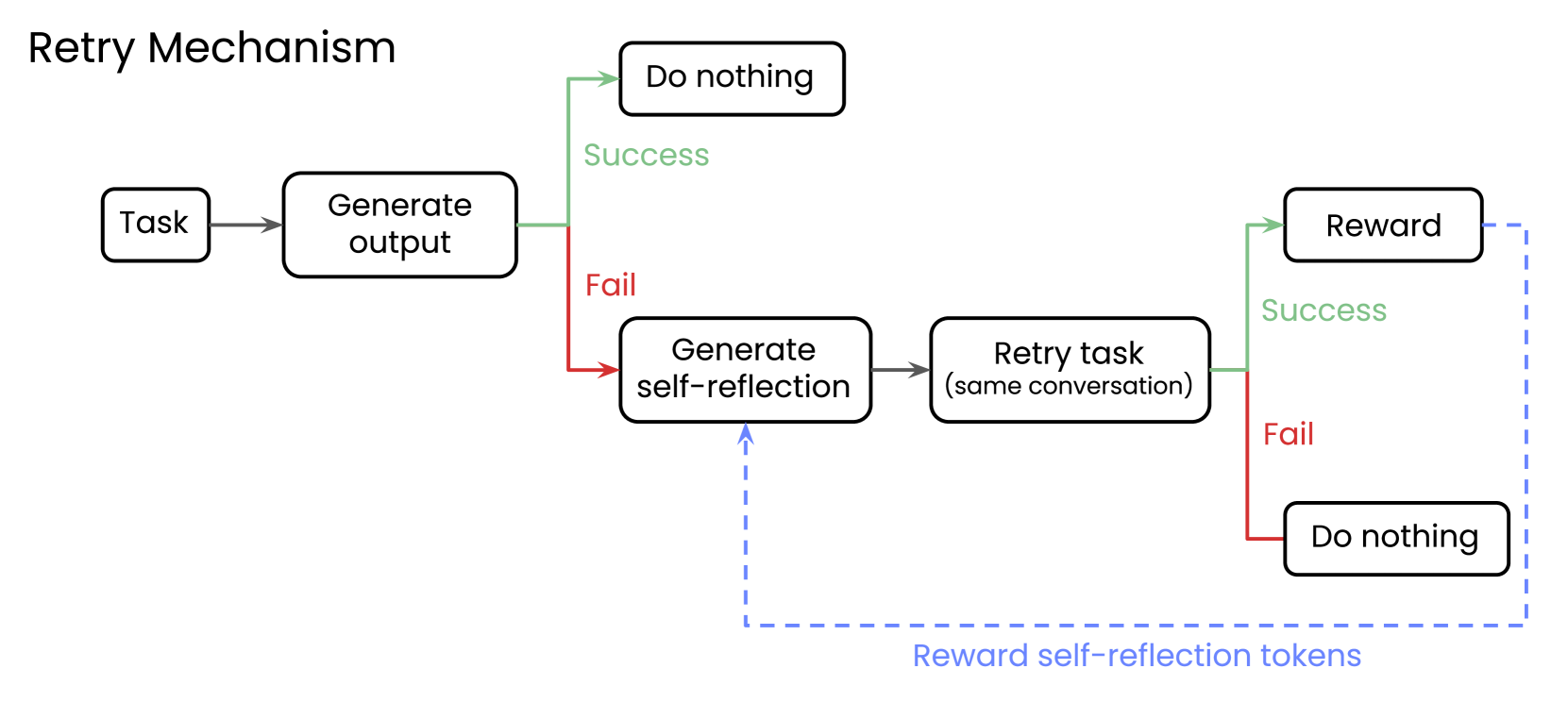
The Reflect, Retry, Reward workflow. It shows the path for a failed query: Failure -> Generate Reflection -> Retry with Reflection -> Success -> Reward Reflection Tokens.
Evaluation Highlights
- +34.7 percentage points improvement on the Countdown math task for Qwen2.5-1.5B-Instruct (23.6% -> 58.3%)
- +18.5 percentage points improvement on APIGen function calling for Llama-3.1-8B-Instruct (67.9% -> 86.4%)
- Small fine-tuned models (e.g., Qwen2.5-7B) outperform vanilla models 10x their size (e.g., Qwen2.5-72B) on these specific verifiable tasks
Breakthrough Assessment
8/10
Significant performance gains on verifiable tasks using a clever, efficient RL setup that requires only binary feedback. The 'masking rewards to target reflection' is a strong methodological contribution.