📝 Paper Summary
Reward Modeling
LLM Alignment
Interpretability
R3 is a reward modeling framework that aligns LLMs by generating interpretable scores and natural language reasoning across point-wise, pair-wise, and binary tasks using rubric-augmented training data.
Core Problem
Current reward models are often optimized for narrow objectives (e.g., just helpfulness), struggle to generalize to new tasks, and output opaque scalar scores without explaining why a response is good or bad.
Why it matters:
- Scalar scores like '0.65' are meaningless without context, making it hard to diagnose model failures
- Models trained on narrow preference data fail to generalize to diverse downstream tasks like code reasoning or fact verification
- Human annotation is costly, and existing datasets lack consistent rubrics or reasoning traces needed for interpretable alignment
Concrete Example:
A reward model might assign a score of 0.6543 to a response. Without a rubric or explanation, it is unclear if this score reflects helpfulness, correctness, or coherence, limiting actionable insight for developers.
Key Novelty
Unified Rubric-Agnostic Reasoning Reward Model
- Standardizes reward modeling into three formats (point-wise, pair-wise, binary) within a single unified framework, allowing one model to handle diverse evaluation tasks
- Utilizes a 'Rubric-Follow-Reasoning' approach where the model is conditioned on explicit rubrics and trained to generate a natural language justification before outputting a score
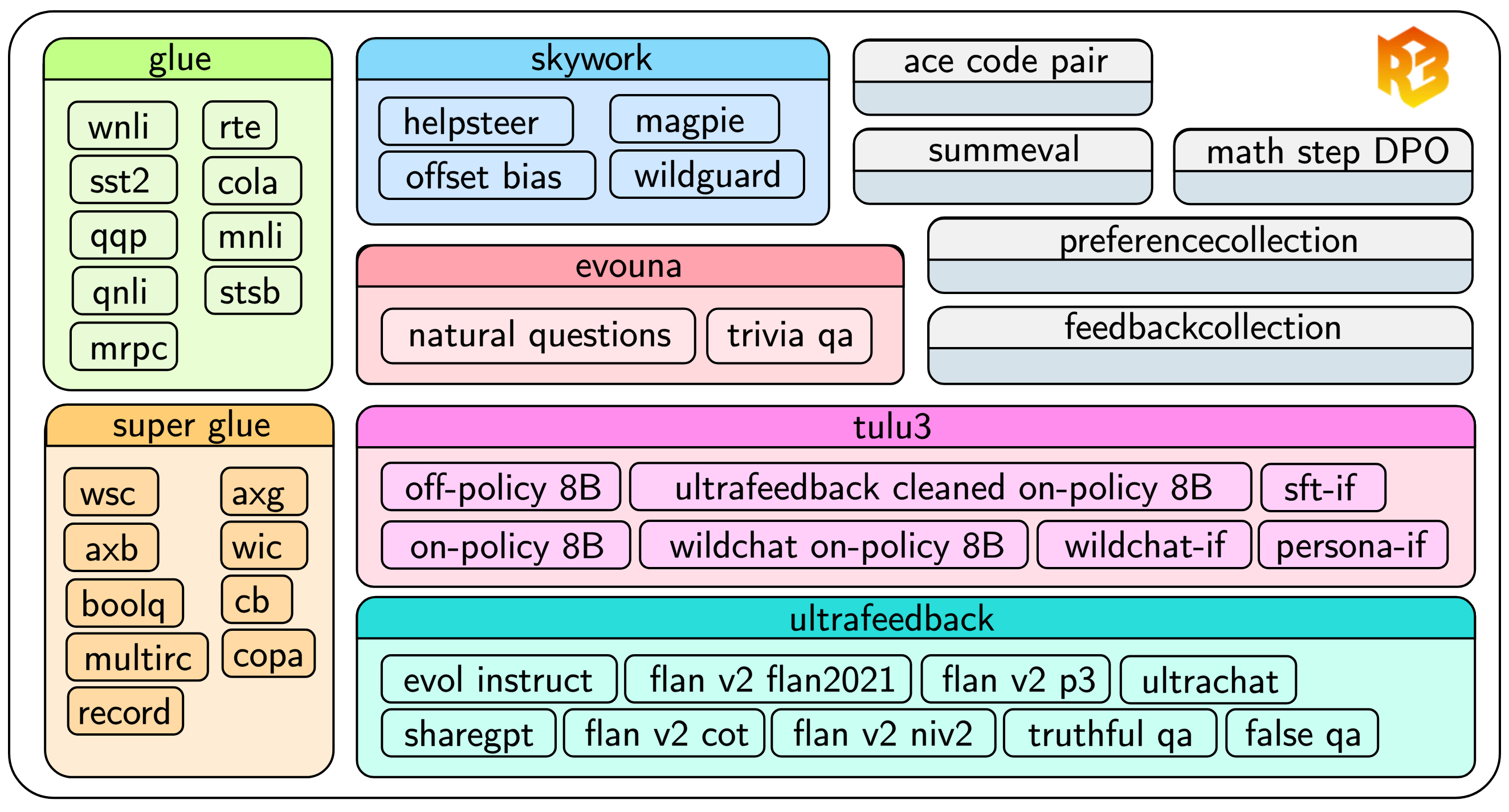
- Curates a new dataset (R3 dataset) by enriching existing data with automatically generated rubrics and distilling reasoning traces from strong reasoning models (DeepSeek-R1)
Architecture
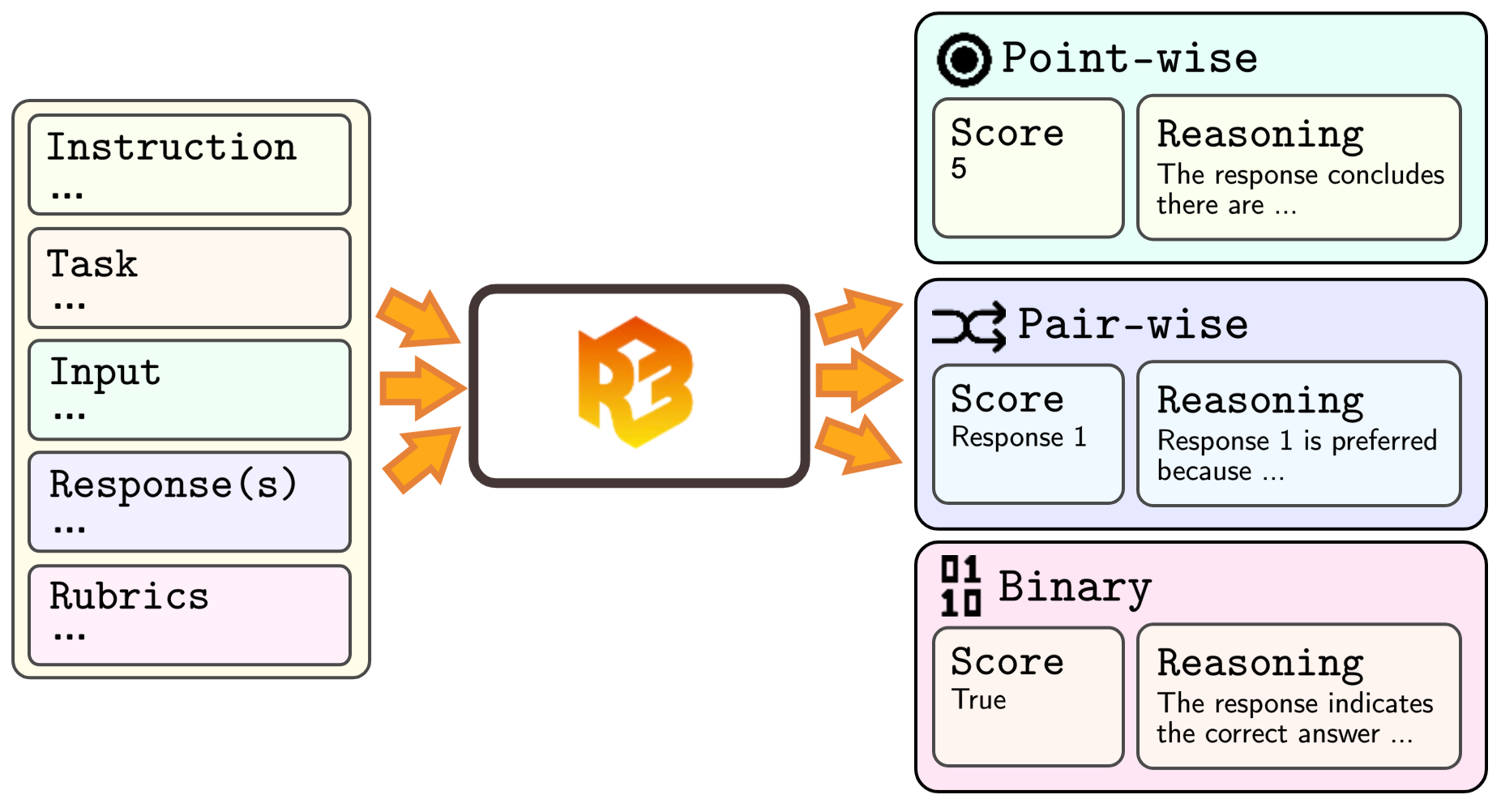
The unified R3 framework pipeline showing inputs, the reasoning generation process, and the final score output.
Evaluation Highlights
- R3-8B achieves 83.7% accuracy on RewardBench, outperforming larger models like InternLM2-20B-Reward (82.4%) and proprietary GPT-4o-mini (81.6%)
- R3-8B reaches 92.5% on the reasoning-heavy RM-Bench, surpassing GPT-4o-mini (89.1%) and the larger DeepSeek-V3 (91.8%)
- Using R3 as a verifier in Best-of-N sampling improves math reasoning (MATH-500) from 54.4% to 62.2% (+7.8%), outperforming standard Qwen2.5-Math-RM
Breakthrough Assessment
8/10
Offers a highly practical, unified solution for interpretable reward modeling. The ability to handle binary, point-wise, and pair-wise tasks with a single model while providing reasoning is a significant step forward for alignment.