📊 Experiments & Results
Evaluation Setup
Train on preference datasets (UltraFeedback/UltraInteract), evaluate on held-out ID splits and OOD benchmark (RewardBench)
Benchmarks:
- UltraFeedback (Held-out) (General Instruction Following (In-Distribution))
- RewardBench (General Reward Model Benchmark (Out-of-Distribution))
- UltraInteract (Reasoning/Math/Code)
Metrics:
- Accuracy (matching human preference labels)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| In-distribution performance on UltraFeedback shows GenRM methods matching traditional approaches. | ||||
| UltraFeedback | Accuracy | 74.0 | 73.9 | -0.1 |
| Out-of-distribution performance on RewardBench demonstrates superior generalization of the STaR-DPO approach. | ||||
| RewardBench (Average) | Accuracy | 77.8 | 81.9 | +4.1 |
| RewardBench (Safety) | Accuracy | 81.8 | 91.0 | +9.2 |
| RewardBench (Reasoning) | Accuracy | 70.8 | 87.2 | +16.4 |
Experiment Figures
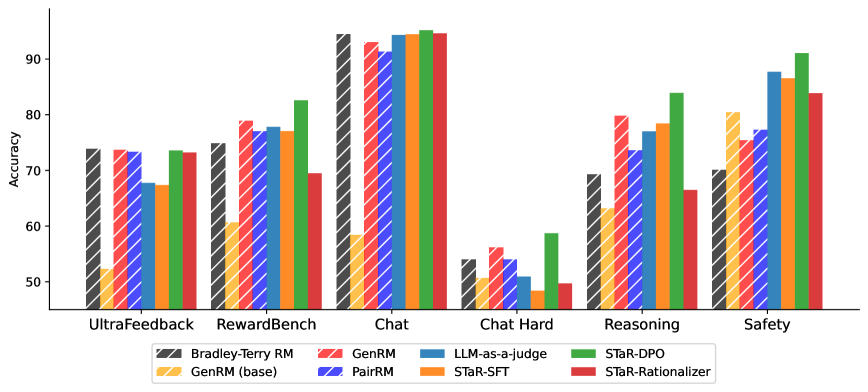
Comparison of accuracies on UltraFeedback (In-Domain) and RewardBench (OOD) across different reward modeling approaches.
Main Takeaways
- Generative Reward Models with STaR-DPO match the in-distribution accuracy of specialized Bradley-Terry models while providing significantly better OOD robustness.
- Training on self-generated reasoning traces (STaR) combined with preference optimization (DPO) is crucial; simple SFT on reasoning traces (STaR-SFT) yields negligible gains over the base model.
- The approach is particularly effective for Safety and Reasoning tasks, where explicit reasoning helps identify nuances that scalar reward models miss.