📝 Paper Summary
Reward Engineering
Robotic Manipulation
Inverse Reinforcement Learning
This paper enables robots to learn physical skills without expert demonstrations by using an LLM to propose a parameterized reward structure and then tuning those parameters by aligning the reward function's ranking of trajectories with the LLM's preferences.
Core Problem
Designing reward functions for physical skills is manual and tedious, while LLM-generated rewards often fail due to poor numerical reasoning and inability to incorporate environmental feedback.
Why it matters:
- Manual reward engineering requires extensive domain knowledge and trial-and-error, bottlenecking the scaling of robotic skills
- Inverse Reinforcement Learning (IRL) relies on expert demonstrations, which are costly and difficult to collect for high-precision physical tasks
- Directly using LLMs to write reward code often results in unstable or physically infeasible rewards because LLMs lack grounding in physical dynamics
Concrete Example:
In a 'pushing' task, a standard LLM might assign a low reward weight (e.g., 2.0) to the pushing action and a high weight to reaching. The robot exploits this by just touching the object without pushing it. The proposed method detects this sub-optimality via ranking and automatically increases the push weight to 21.05 to force the correct behavior.
Key Novelty
Iterative Self-Alignment for Reward Parameterization
- Decomposes reward learning into two steps: (1) LLM generates a Python reward template with tunable hyperparameters (feature selection), and (2) An iterative loop tunes these parameters by asking the LLM to rank robot trajectories
- Treats the LLM not just as a code generator, but as a 'discriminator' or pseudo-expert that provides preference feedback to guide the numerical optimization of the reward function
- Uses a 'failure analysis' prompt when rankings agree but the task fails, explicitly asking the LLM to identify blocking factors and suggest parameter updates
Architecture
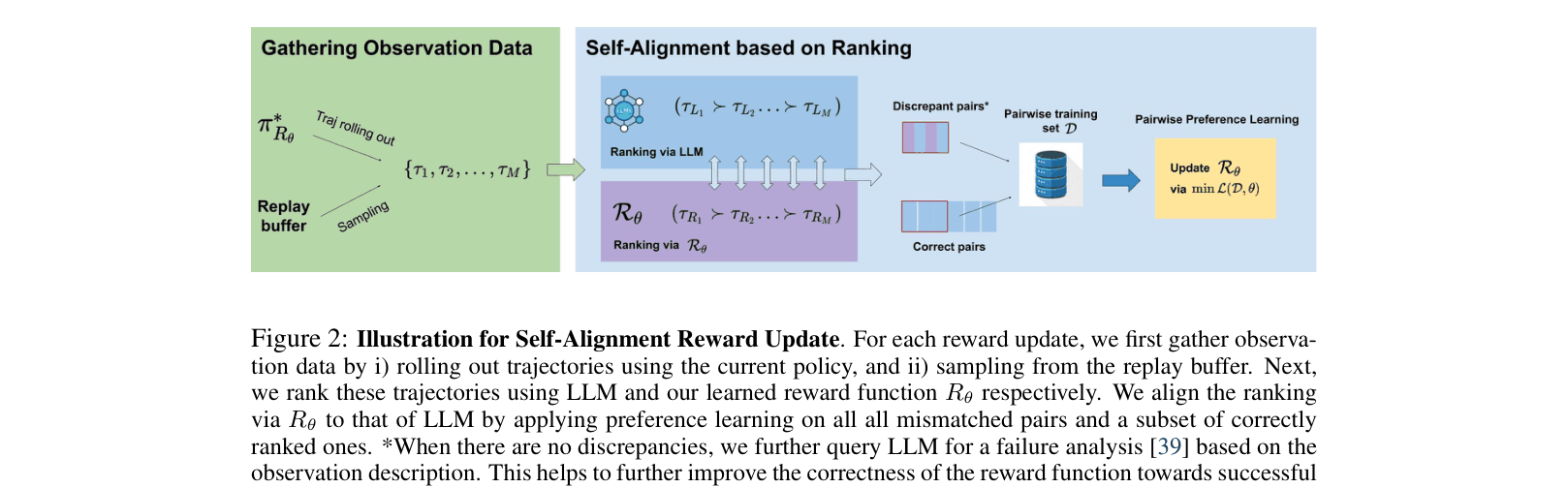
The Self-Alignment Reward Update process (Algorithm 1) showing the interaction between the policy, replay buffer, and LLM.
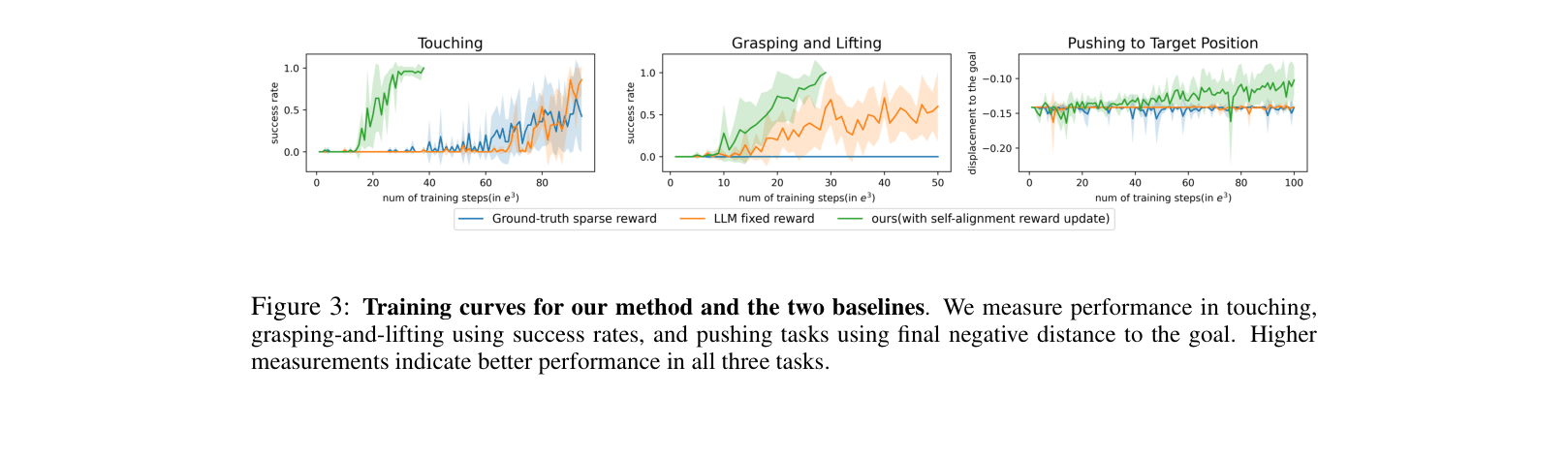
Evaluation Highlights
- Touching task: Reaches 100% success in ~24,600 steps using Self-Alignment, compared to 93,200 steps for the fixed LLM-generated reward (approx. 3.8x faster)
- Grasping task: Achieves 100% success in 19,000 steps, whereas the sparse reward baseline fails to learn the task entirely within the compute budget
- Pushing task: Automatically corrects a sub-optimal 'touch-only' policy by identifying the need to increase pushing weight from 2.0 to 21.05 via preference alignment
Breakthrough Assessment
7/10
A clever integration of LLMs as both architects (code generation) and critics (ranking), addressing the specific weakness of LLM numerical reasoning in robotics. Limited by simulation-only validation.