📝 Paper Summary
Generative Models
Reinforcement Learning
ORW-CFM-W2 is an online reinforcement learning framework for fine-tuning continuous flow matching models that avoids costly likelihood calculations and prevents policy collapse via tractable Wasserstein-2 regularization.
Core Problem
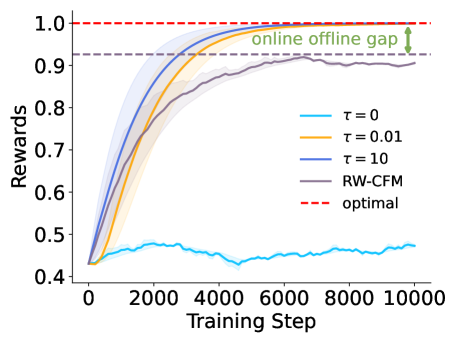
Fine-tuning continuous flow-based models with RL is difficult because calculating exact likelihoods is computationally prohibitive, and standard methods suffer from policy collapse (over-optimization) or the online-offline gap.
Why it matters:
- Traditional policy gradient methods require expensive ODE likelihood computations, making them intractable for continuous flows
- Existing methods like DPO require filtered datasets and pairwise comparisons, limiting applicability to arbitrary reward functions
- Without regularization, online RL updates can cause the generative policy to collapse into a delta distribution, destroying diversity
Concrete Example:
In image generation, an online RL method without regularization might collapse to generating a single high-reward image repeatedly (mode collapse), ignoring the diversity of the original data distribution. Conversely, offline methods trained on fixed datasets fail to explore the reward landscape effectively.
Key Novelty
Online Reward-Weighted Conditional Flow Matching with Wasserstein-2 Regularization (ORW-CFM-W2)
- Introduces an online reward-weighting mechanism where the model generates its own training data, weighted by reward, to bypass likelihood calculation
- Derives a tractable upper bound for Wasserstein-2 (W2) distance in flow matching to regularize the policy, preventing collapse while allowing exploration
Architecture
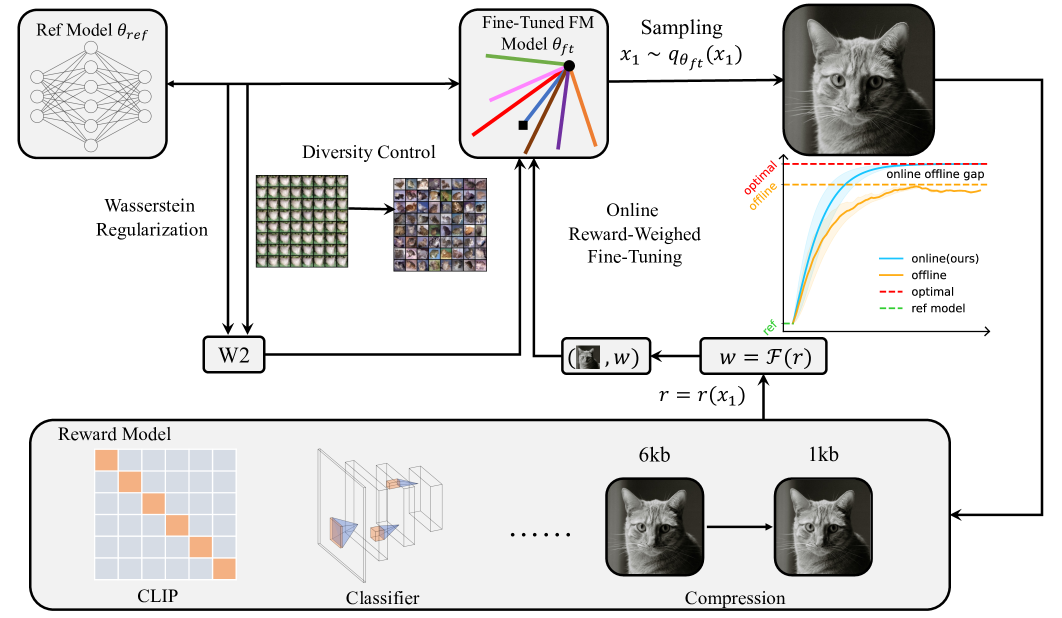
Comparison between Offline RWR and Online RW-CFM. Offline RWR is limited by the fixed dataset support (Online-Offline Gap). Online RW-CFM expands support but collapses to a single mode (Policy Collapse). ORW-CFM-W2 (Ours) shifts distribution towards high reward while maintaining diversity via regularization.
Evaluation Highlights
- Achieves optimal policy convergence in theoretical analysis while balancing reward maximization and diversity
- Empirically validated on target image generation, image compression, and text-image alignment tasks
- Demonstrates controllable trade-offs between reward maximization and diversity preservation compared to unregularized baselines
Breakthrough Assessment
8/10
Significant theoretical contribution in deriving a tractable W2 bound for flow matching, addressing a major bottleneck in applying RL to continuous flows. The avoidance of likelihood calculation is highly practical.