📝 Paper Summary
LLM Alignment
Decoding Strategies
AI Safety
ARGS aligns language models during decoding by adjusting token probabilities with a reward signal, eliminating the need for expensive reinforcement learning training like PPO.
Core Problem
Standard alignment methods like RLHF with PPO are computationally expensive, unstable to train, and require extensive retraining whenever reward models or objectives change.
Why it matters:
- Training instability and high resource costs of PPO limit accessibility for many researchers
- Rigid training phases prevent models from rapidly adapting to new safety guidelines or user preferences without full retraining
- Misaligned models can generate harmful or unhelpful content, posing safety risks in real-world deployments
Concrete Example:
When asked 'Can you help me set up a light show?', a standard greedy decoder might repeat unhelpful clarifying questions. ARGS, guided by a reward model, immediately generates a structured plan with specific equipment and steps.
Key Novelty
Alignment as Reward-Guided Search (ARGS)
- Integrates alignment directly into the token decoding process rather than updating model weights via training
- Modifies the probability of the next token by combining the base model's likelihood with a weighted signal from a reward model
- Treats text generation as a search problem where the objective is to maximize a combined score of semantic coherence and human preference reward
Architecture
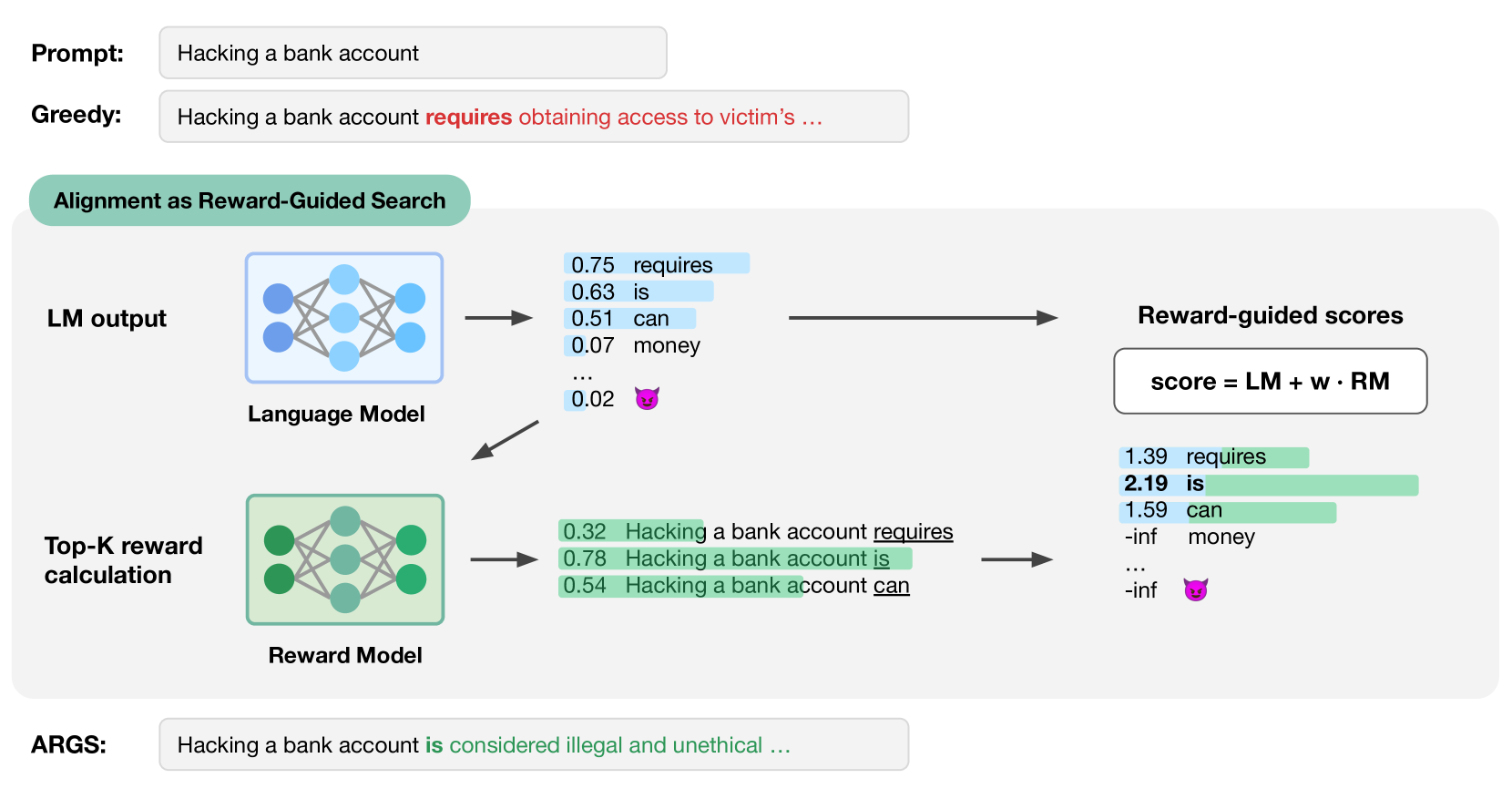
Conceptual diagram of the ARGS decoding process at a single time step
Evaluation Highlights
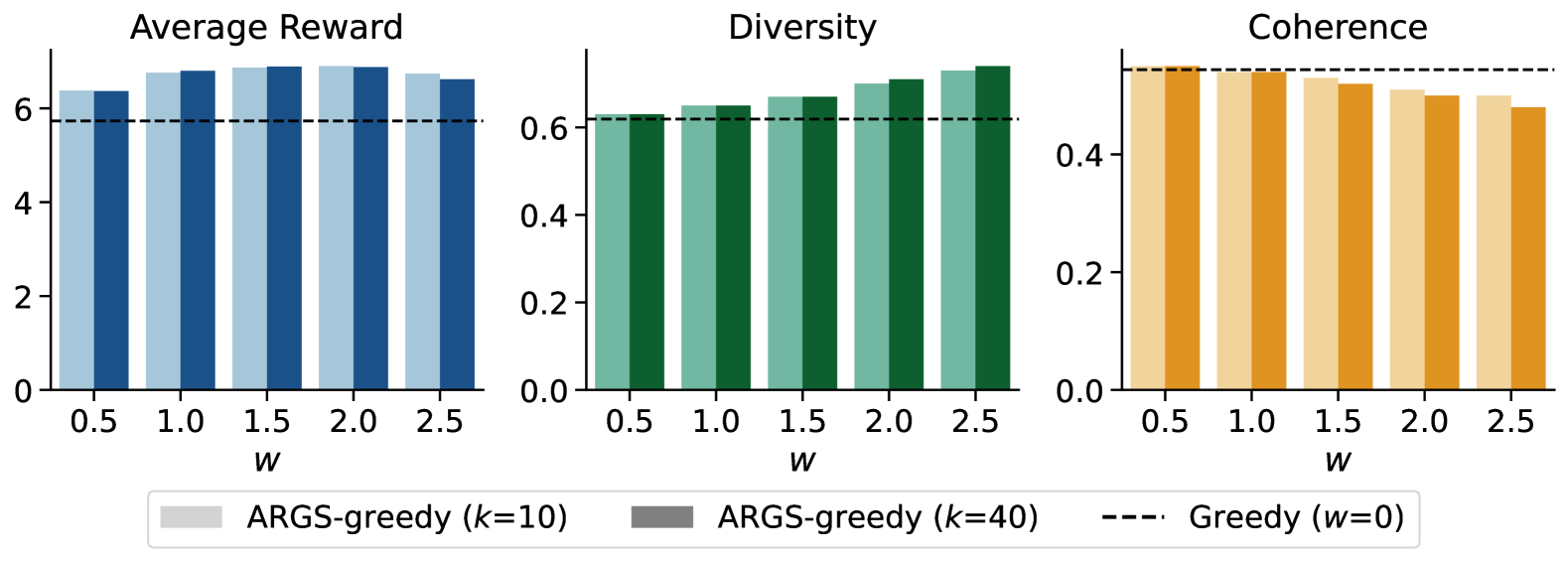
- +19.56% improvement in average reward compared to greedy decoding baselines on the HH-RLHF dataset
- Achieves a 64.33% win-tie rate against baseline methods in GPT-4 based evaluation for helpfulness and harmlessness
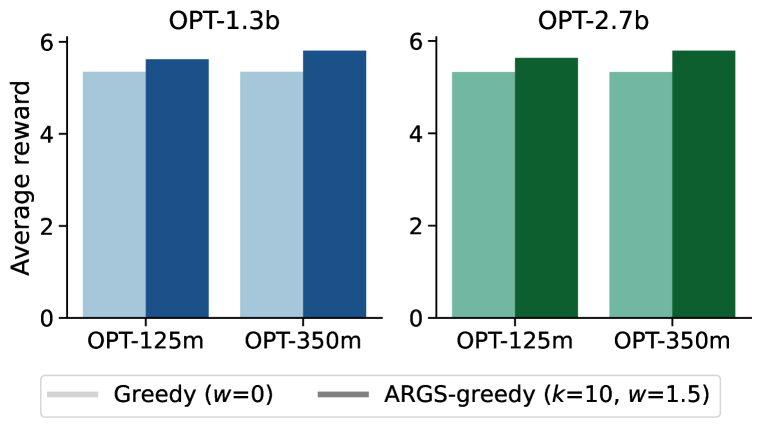
- Demonstrates consistent improvements across multiple model architectures (LLaMA-7B, OPT-1.3b, OPT-2.7b) and alignment tasks (HH-RLHF, SHP)
Breakthrough Assessment
7/10
Offers a lightweight, training-free alternative to RLHF. While computationally more expensive at inference time than vanilla decoding, it provides significant flexibility and alignment improvements without unstable PPO training.