📝 Paper Summary
Visual Generation
Reward Modeling
Reinforcement Learning from Human Feedback (RLHF)
RewardDance reformulates visual reward modeling as a scalable generative task—predicting 'yes' tokens for preferred images—enabling effective scaling of model size and context to improve diffusion model alignment.
Core Problem
Existing visual reward models suffer from paradigm mismatch: regression heads on Vision-Language Models (VLMs) misalign with next-token prediction, while CLIP-based models struggle to scale.
Why it matters:
- Regression-based reward models are highly susceptible to 'reward hacking', where generators exploit flaws in the reward signal without improving true quality.
- Current approaches fail to leverage the full reasoning capabilities of large VLMs because they reduce complex preference judgments to a single scalar output.
- Lack of scalability prevents visual generation from benefiting from the 'scaling laws' that have driven progress in LLMs.
Concrete Example:
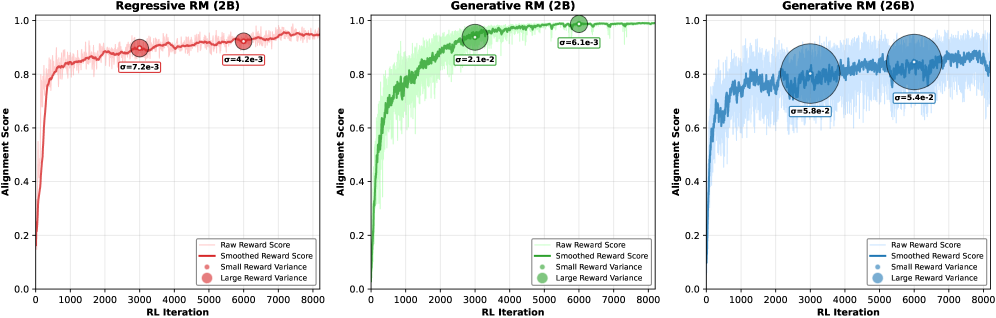
In Figure 2, a regression-based reward model's score increases during RLHF training, but the actual human preference win-rate collapses, showing the model is 'hacking' the reward metric rather than generating better images.
Key Novelty
Generative Reward Modeling with Dual Scaling
- Redefines reward calculation as a generative next-token prediction task (predicting the probability of a 'yes' token given a comparison prompt), aligning natively with VLM architectures.
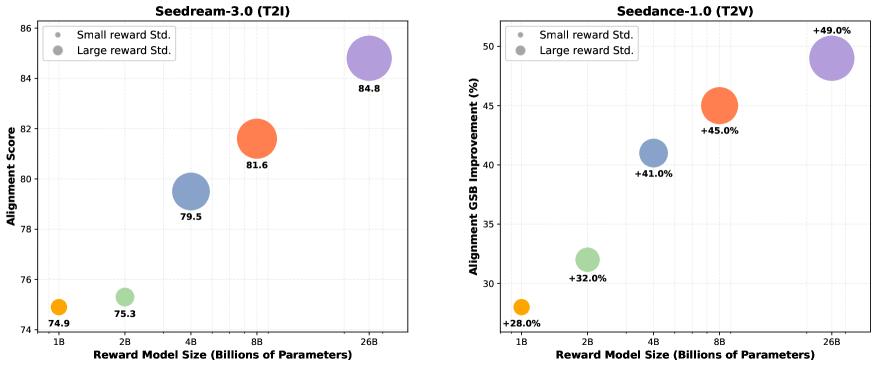
- Scales reward modeling across two dimensions: Model Scaling (systematically increasing parameters from 1B to 26B) and Context Scaling (incorporating task instructions, reference images, and Chain-of-Thought reasoning).
Architecture
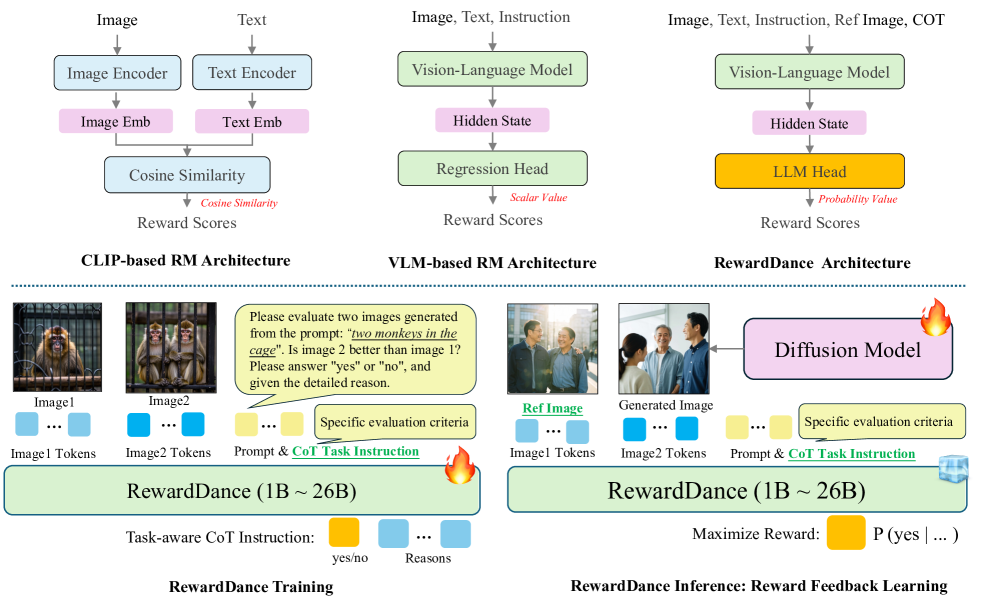
Comparison of traditional Pointwise Regressive Reward Models vs. the proposed Generative RewardDance framework.
Evaluation Highlights
- Significant improvements in generation quality across text-to-image, text-to-video, and image-to-video tasks compared to state-of-the-art baselines.
- Scaling the Reward Model to 26B parameters drastically reduces reward hacking, maintaining high reward variance and correlation with human preference even at high RL training steps.
- Integration of Chain-of-Thought (CoT) reasoning data enables the reward model to provide interpretable feedback, further boosting accuracy over simple preference pairs.
Breakthrough Assessment
9/10
Establishes a new scaling law for visual reward models, proving that generative RMs scale effectively up to 26B parameters and solve the critical reward hacking problem plaguing RLHF in vision.