📝 Paper Summary
Model-Based Reinforcement Learning (MBRL)
Reward Modeling
Sparse Rewards
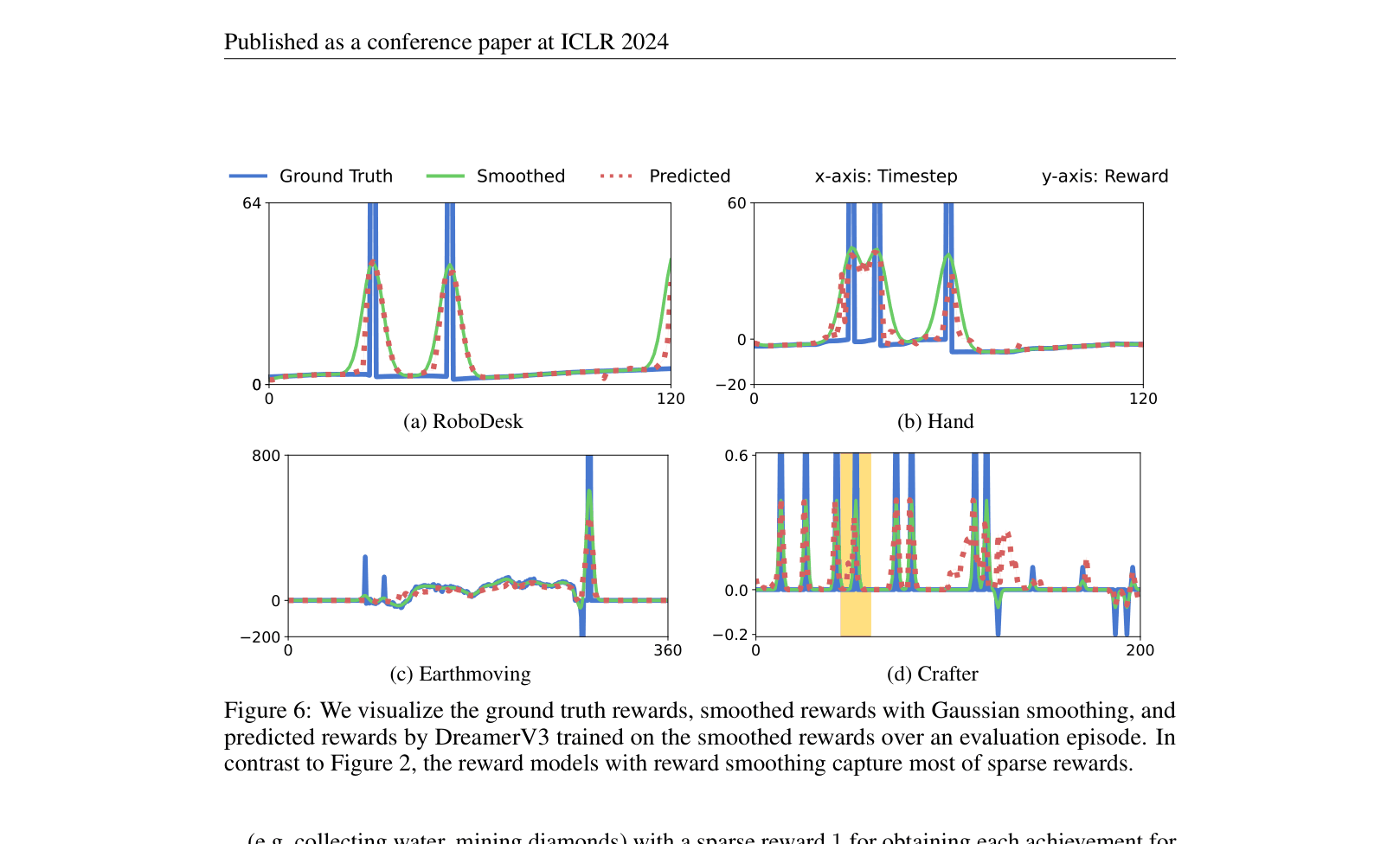
DreamSmooth simplifies reward prediction in model-based RL by training the reward model on temporally smoothed rewards, making it easier to detect sparse or ambiguous signals.
Core Problem
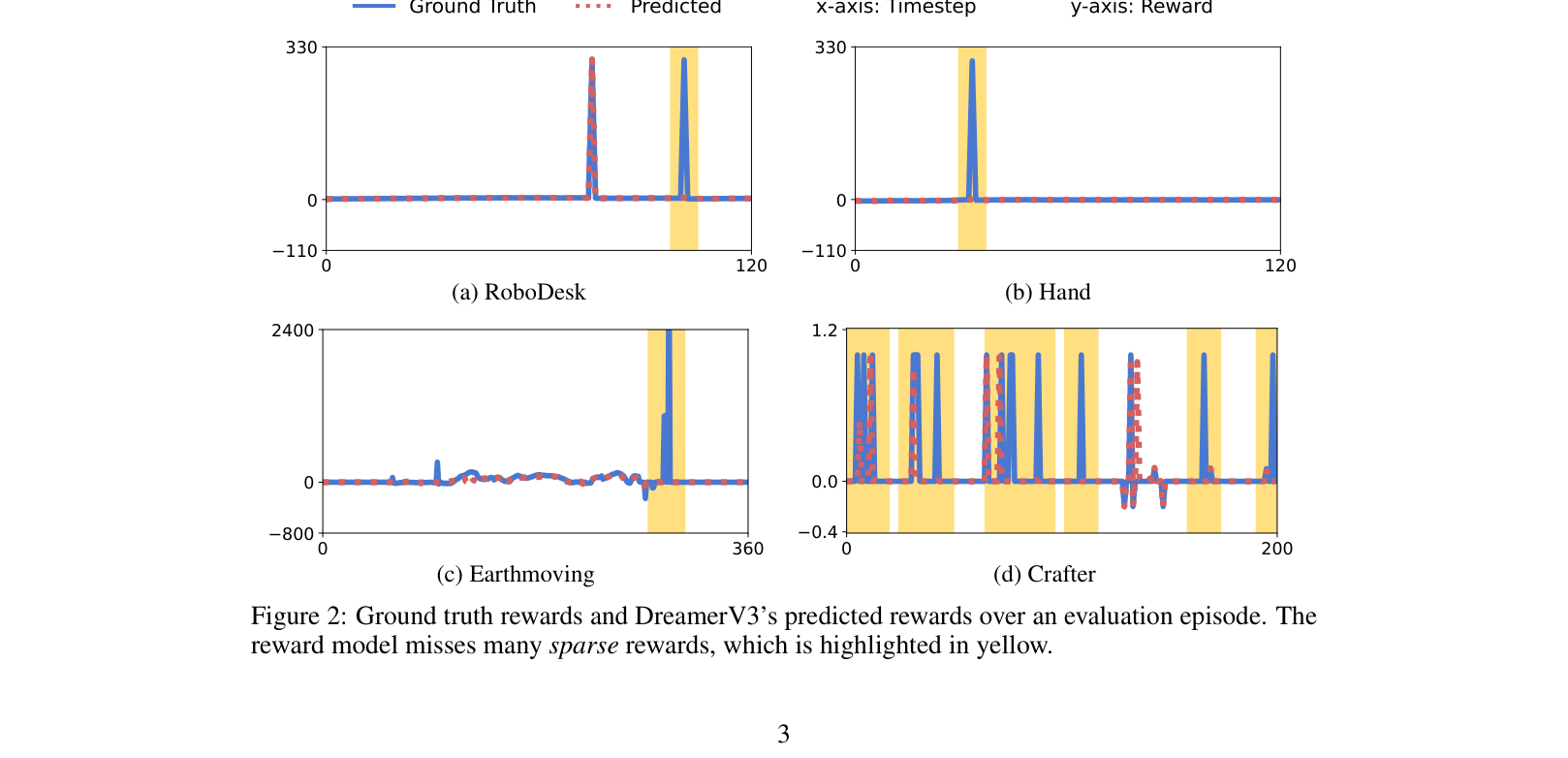
In model-based RL, predicting exact sparse rewards at precise timesteps is extremely difficult due to ambiguity and partial observability, causing models to collapse and predict zero reward.
Why it matters:
- Current state-of-the-art MBRL algorithms like DreamerV3 fail on tasks with sparse rewards because the reward model misses the signal entirely
- Without an accurate reward model, the critic cannot learn properly, and the agent's policy fails to optimize for the actual task objective
- Predicting the exact millisecond a reward occurs is often unnecessary for successful planning; a rough estimate is sufficient
Concrete Example:
In the 'RoboDesk' task, a large reward is given only when a block touches a bin. This moment is visually ambiguous and spans only a single timestep. Standard reward models fail to predict this spike, outputting near-zero values, so the agent never learns to push the block into the bin.
Key Novelty
Temporal Reward Smoothing for MBRL
- Instead of training the reward model to predict the exact reward $r_t$ at step $t$, train it to predict a temporally smoothed version (e.g., Gaussian blur over neighboring steps)
- This relaxes the learning objective: the model only needs to predict *roughly when* a reward occurs, rather than the exact ambiguous timestep, preventing model collapse on sparse signals
Architecture
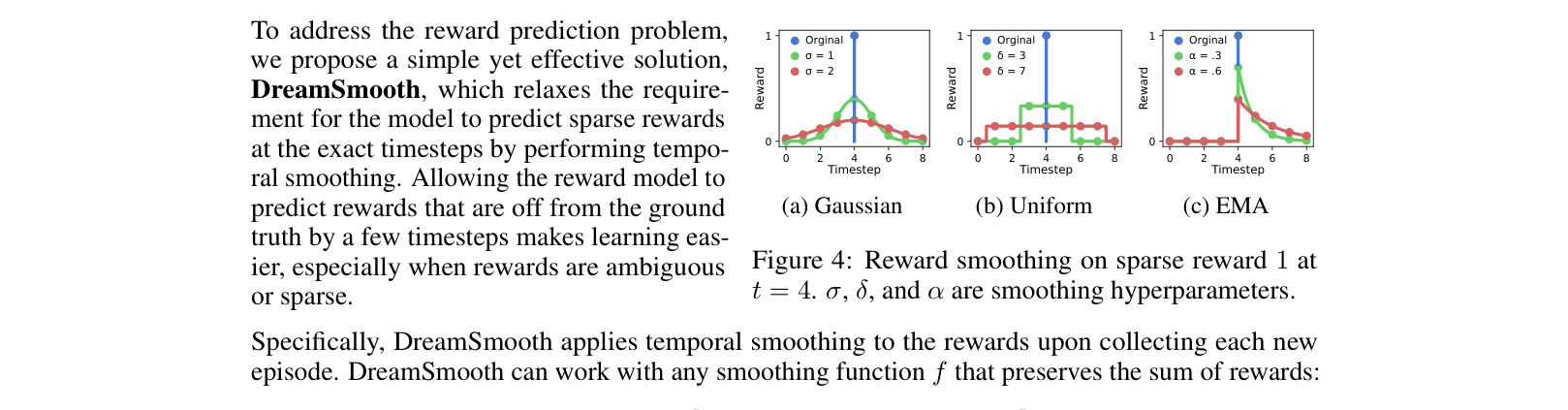
Illustration of three smoothing functions (Gaussian, Uniform, EMA) applied to a sparse reward signal
Evaluation Highlights
- Achieves near 100% task completion on sparse-reward RoboDesk and Hand tasks where baseline DreamerV3 fails completely (0% success)
- Improves reward prediction accuracy in Crafter (15/19 achievements predicted better), though this does not always translate to higher game scores
- Maintains performance on standard dense-reward benchmarks (DeepMind Control Suite, Atari) without degradation
Breakthrough Assessment
7/10
Simple, highly effective fix for a specific but common failure mode (sparse/ambiguous rewards) in MBRL. While not a new architecture, it unlocks performance on tasks where SOTA methods previously failed.