📝 Paper Summary
Mathematical Reasoning
Reward Modeling
R-PRM improves mathematical reasoning evaluation by training a model to generate detailed natural language analysis for each step before assigning a score, rather than predicting scores directly.
Core Problem
Existing Process Reward Models (PRMs) predict correctness scores directly from steps, which limits interpretability and learning efficiency, and they suffer from a scarcity of high-quality human-annotated process data.
Why it matters:
- Direct scalar scoring provides no feedback on *why* a step is wrong, making it harder for models to learn complex reasoning patterns.
- High-quality step-level annotation is expensive and scarce; automated methods (like Monte Carlo) are computationally heavy and noisy.
- Accurate process supervision is critical for guiding LLMs through complex multi-step mathematical problems where one early error invalidates the whole solution.
Concrete Example:
In a complex algebra problem, a standard PRM might assign a low score to a step without explanation. R-PRM explicitly generates an analysis stating 'The step incorrectly expands the polynomial (x+y)^2 as x^2+y^2 instead of x^2+2xy+y^2,' then assigns the 'no' label.
Key Novelty
Reasoning-Driven Process Reward Modeling (R-PRM)
- Instead of just outputting a scalar score, the model is trained to generate a multi-dimensional analysis (checking history, logic, calculation) followed by a 'yes/no' judgment.
- Uses a strong teacher model (LLaMA3.3-70B) to synthesize reasoning traces for seed data, bootstrapping from limited human annotations.
- Applies preference optimization (DPO) to the *evaluation process* itself, encouraging the generation of reasoning traces that lead to correct judgments.
Architecture
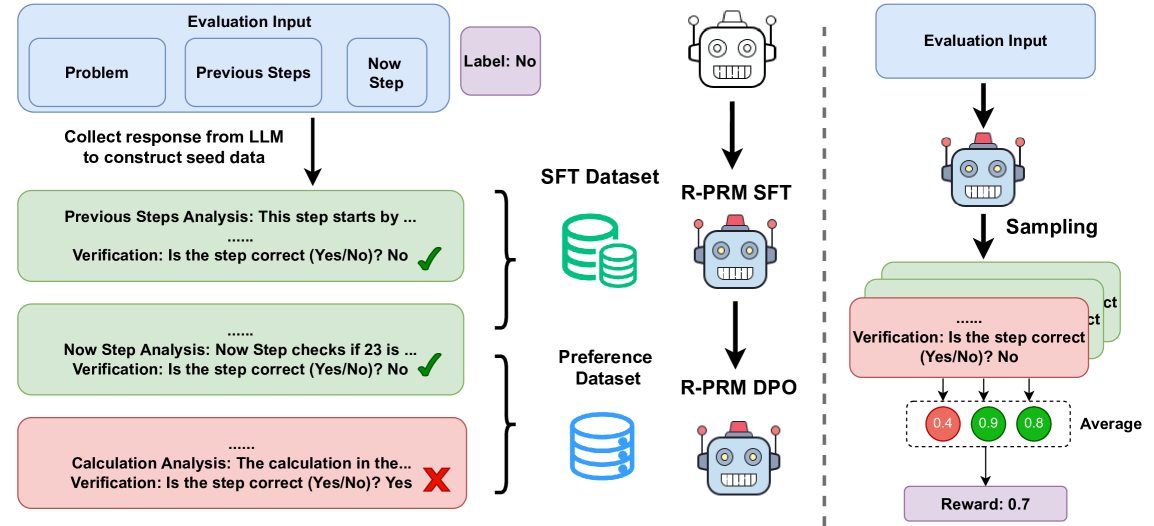
Conceptual flow of the R-PRM evaluation process compared to standard PRMs.
Evaluation Highlights
- +11.9 F1 score improvement on ProcessBench compared to the strongest baseline (Qwen2.5-Math-7B-PRM800K).
- +8.6% average accuracy improvement over Pass@1 baseline across six math datasets when used for Best-of-N sampling.
- Outperforms GPT-4o by 3.3 points in F1 score on ProcessBench, demonstrating superior error detection capability.
Breakthrough Assessment
8/10
Significantly outperforms strong baselines and even GPT-4o on process evaluation benchmarks. The shift from direct scoring to 'reasoning about reasoning' is a logically sound and effective advancement for PRMs.