📝 Paper Summary
Language Model Alignment
Reinforcement Learning from AI Feedback (RLAIF)
RLCF aligns language models by replacing opaque reward models with interpretable, instruction-specific checklists generated by a teacher model, enabling precise grading via AI judges and code verifiers.
Core Problem
Standard Reinforcement Learning (RL) for instruction following relies on reward models that are often arbitrary, susceptible to reward hacking, or limited to verifiable tasks, failing to capture subjective or complex multi-step constraints.
Why it matters:
- Reward models often act as black boxes, making it difficult to understand why a model is penalized or rewarded
- Existing methods using only verifiable instructions (like math) ignore subjective quality aspects like style or tone
- Distilling preferences from larger models reduces the 'generator-verifier gap,' limiting how much the student can improve beyond the teacher's generation capabilities
Concrete Example:
When a user asks to translate text to Spanish, a standard AI judge might give a high score to a response that is fluent but contains hallucinations. RLCF splits this into a checklist (e.g., 'Is it in Spanish?', 'Is the meaning preserved?'), using code to verify the language constraint and an LLM for meaning, catching errors a single score misses.
Key Novelty
Reinforcement Learning from Checklist Feedback (RLCF)
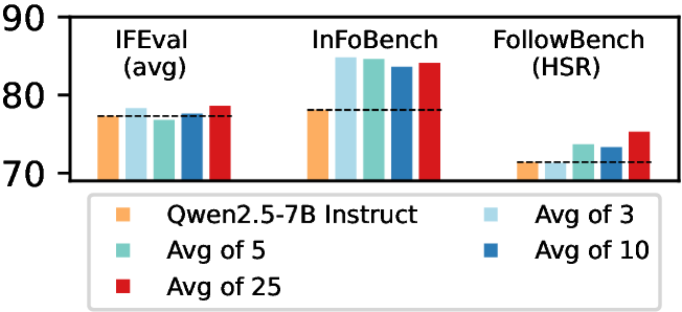
- Dynamically generates a checklist of specific 'yes/no' requirements for every instruction using a candidate-based method (generating failure modes from draft responses)
- Grades responses by combining an LLM judge (for subjective items) and executable code verifiers (for objective constraints like 'contains 3 commas')
- Uses the weighted average of these checklist items as a fine-grained reward signal for preference tuning, rather than a single scalar score from a reward model
Architecture
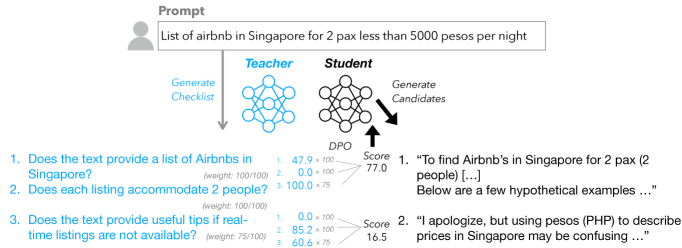
The RLCF pipeline: Checklist Generation -> Response Scoring -> Preference Tuning.
Evaluation Highlights
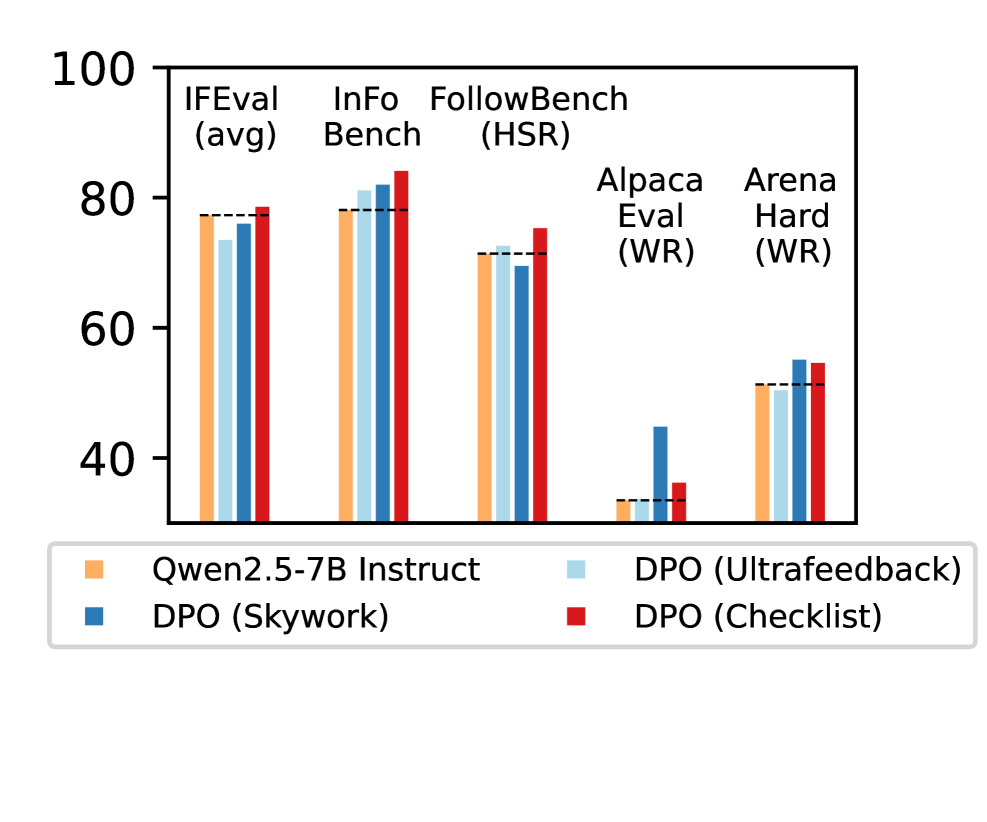
- +8.2% relative improvement on FollowBench Constraint Satisfaction Level compared to the base Qwen2.5-7B-Instruct model
- +6.4% relative improvement on Arena-Hard win rates, outperforming standard RLHF methods
- Consistent gains across all 5 benchmarks tested (IFEval, InFoBench, FollowBench, AlpacaEval, Arena-Hard), whereas baseline reward models like Skywork and ArmoRM showed mixed results or regressions
Breakthrough Assessment
8/10
Strong empirical results across diverse benchmarks showing RLCF is more robust than state-of-the-art reward models. The method is fully synthetic and interpretable, addressing a major bottleneck in alignment.