📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reward Modeling
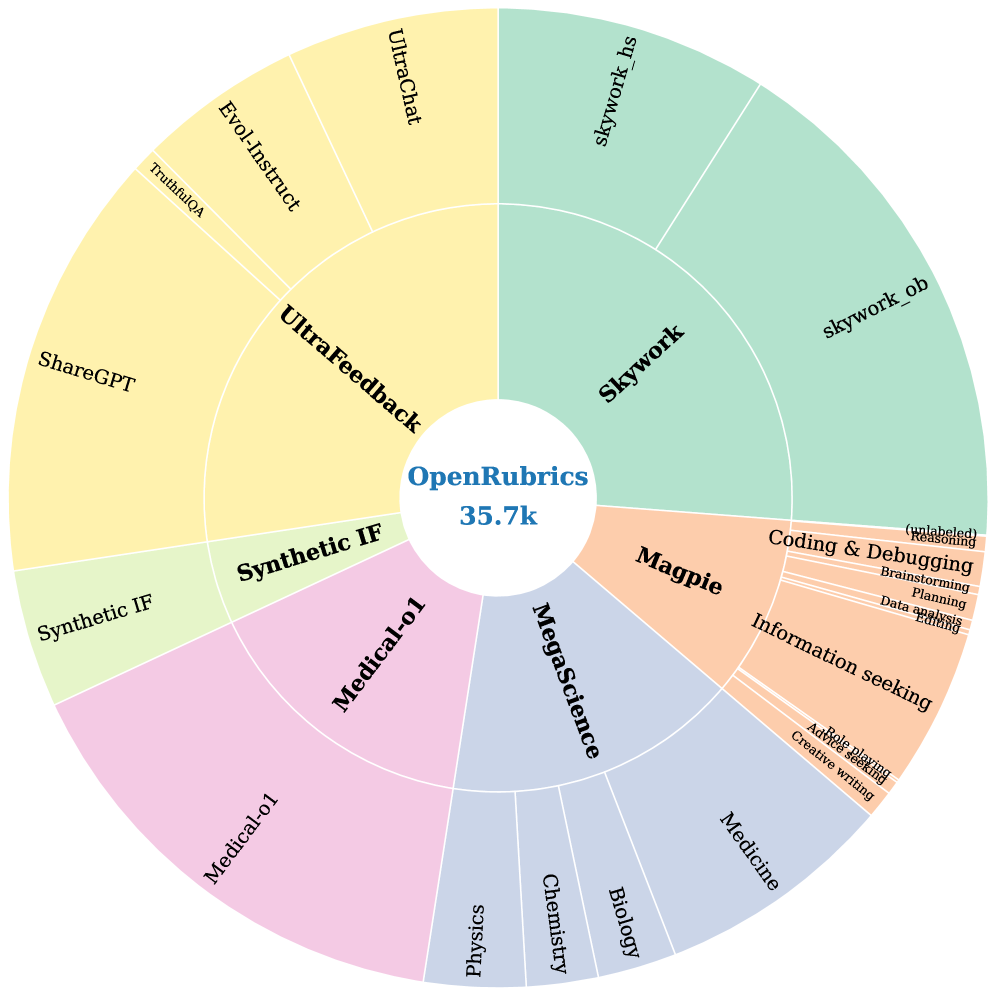
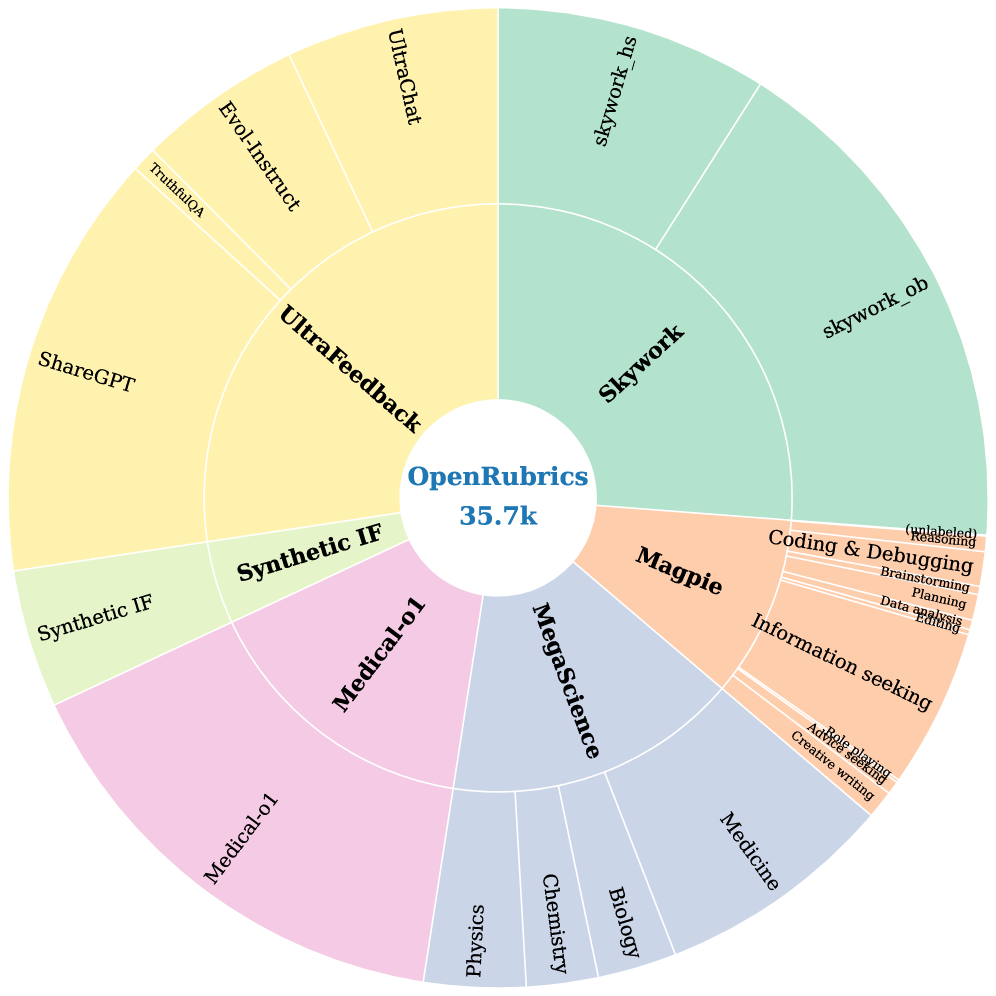
OpenRubrics improves reward modeling by synthesizing structured evaluation criteria (rubrics) via contrastive analysis of response pairs and filtering them for consistency with human preferences.
Core Problem
Standard reward models output opaque scalar scores that fail to capture multifaceted human preferences, while existing rubric-based methods are either expensive to curate manually or lack quality control when synthesized.
Why it matters:
- Scalar rewards provide binary signals (correct/incorrect) that are insufficient for subjective tasks like general helpfulness or long-form QA
- Directly prompting LLMs for rubrics often yields generic or noisy criteria that do not align with actual human preference rankings
- High-quality rubrics are needed to make reward signals interpretable and to guide policy models with explicit principles rather than black-box scores
Concrete Example:
In long-form question answering, a standard reward model might favor an overly long, confident response even if it drifts from the prompt. OpenRubrics generates specific constraints (e.g., 'must be concise', 'must address part X') that help the model identify and penalize such verbosity, reducing false positives.
Key Novelty
Contrastive Rubric Generation (CRG) with Preference Consistency
- Derives rubrics by prompting an LLM to compare 'chosen' vs. 'rejected' responses, explicitly asking what criteria distinguish the better answer (Contrastive Rubric Generation)
- Separates criteria into 'Hard Rules' (explicit constraints from the prompt) and 'Principles' (implicit quality dimensions like tone or reasoning)
- Filters synthesized rubrics by checking 'Preference-Label Consistency': a rubric is kept only if a judge using that rubric correctly predicts the original human preference label
Architecture

The OpenRubrics framework, illustrating the two-stage process: dataset construction via Contrastive Rubric Generation and Rubric-RM training.
Evaluation Highlights
- Rubric-RM-8B achieves 70.1 average on reward benchmarks, outperforming strong size-matched baselines (max 61.7) by 8.4 points
- Rubric-RM-8B-voting@5 (ensemble) reaches 73.0 average, surpassing the much larger RM-R1-14B (71.7)
- +3.5 point improvement on IFEval (79.5 vs 76.0) when using Rubric-RM for policy optimization compared to Skywork/ArmoRM baselines
Breakthrough Assessment
8/10
Strong empirical gains (+8.4% over baselines) and a logically sound methodology (contrastive generation + consistency filtering) that addresses the key bottleneck of scalability in rubric-based rewards.