📝 Paper Summary
Robust Reinforcement Learning
Average-Reward MDPs
Model-Free Reinforcement Learning
This paper introduces the first model-free algorithms for robust average-reward MDPs by using multi-level Monte-Carlo estimators to handle non-linear robust Bellman operators.
Core Problem
Standard RL fails under model mismatch (sim-to-real gap), but existing robust RL methods are either model-based (assuming known uncertainty sets) or restricted to discounted settings, leaving a gap for average-reward tasks like queuing or inventory control.
Why it matters:
- Average-reward criteria are often more suitable than discounted criteria for continuing tasks (e.g., inventory management, communication networks) but are mathematically harder to optimize robustly.
- Model-based methods are impractical when the uncertainty set is not explicitly known and only samples from a nominal model are available.
- Non-linear robust Bellman operators bias standard sample-based estimators, causing naive model-free approaches to fail.
Concrete Example:
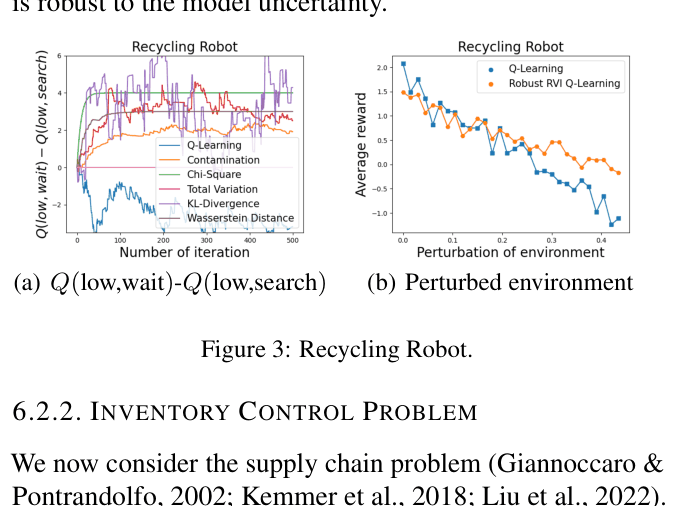
In a recycling robot task, a standard agent learns to 'search' for cans assuming a high success probability. If the environment shifts and searching becomes less reliable, the agent fails. The proposed robust agent learns to 'wait', which yields lower nominal reward but prevents catastrophic failure in the worst-case environment.
Key Novelty
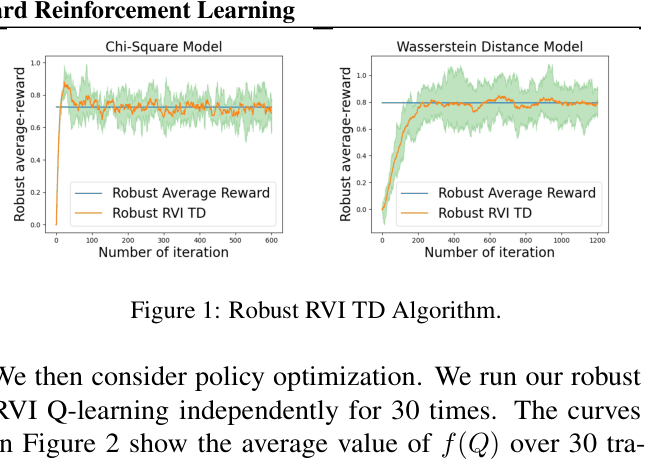
Robust RVI TD and Q-learning with Multi-level Monte-Carlo Estimators
- Characterizes the solution structure of the robust average-reward Bellman equation, showing any solution is a relative value function for some worst-case kernel.
- Adapts Relative Value Iteration (RVI) to the robust setting by introducing an offset function to stabilize the non-contractive average-reward updates.
- Employs Multi-level Monte-Carlo (MLMC) to construct unbiased, bounded-variance estimators for non-linear robust operators (e.g., KL divergence, Wasserstein), overcoming the bias inherent in naive plug-in estimators.
Architecture
The pseudocode for Robust RVI TD and Robust RVI Q-learning, defining the iterative update rules.
Evaluation Highlights
- Robust RVI Q-learning converges to the optimal robust average-reward on Garnet problems, matching model-based ground truth.
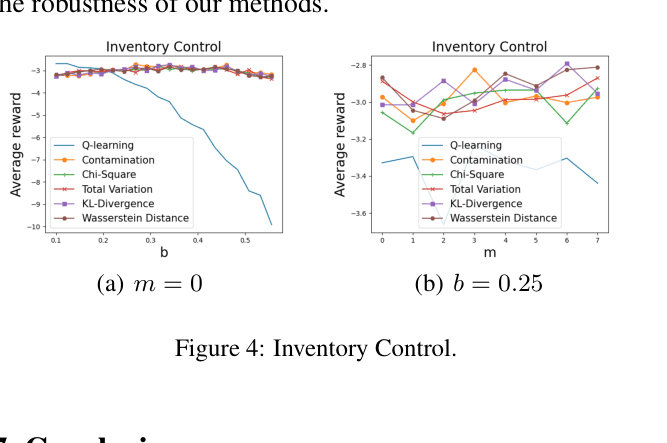
- In an Inventory Control task, the robust policy maintains positive profitability under severe demand distribution shifts (perturbation magnitude b=0.25), while standard Q-learning performance degrades significantly.
- In a Recycling Robot task, the robust agent switches to a conservative 'wait' policy that is stable across perturbed environments, whereas standard Q-learning retains a risky 'search' policy that fails when parameters change.
Breakthrough Assessment
8/10
Fills a significant theoretical gap by providing the first model-free algorithms for robust average-reward MDPs with rigorous convergence proofs and practical estimators for five different uncertainty sets.