📊 Experiments & Results
Evaluation Setup
Mathematical reasoning across varied difficulty levels
Benchmarks:
- MATH500 (Challenging math problems)
- AIME 2024 (Competition math (High difficulty))
- AMC 2023 (Competition math (Medium difficulty))
- OlympiadBench (Olympiad-level math)
Metrics:
- Accuracy (%)
- Average Generation Length (tokens)
- Pareto-optimality (Accuracy vs Length trade-off)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Results for DeepSeek-R1-Distill-Qwen-1.5B show Laser-DE improves accuracy and efficiency on the hardest benchmark (AIME) compared to the original model. | ||||
| AIME 2024 | Accuracy (%) | 28.9 | 35.0 | +6.1 |
| AIME 2024 | Generation Length | 15956 | 5789 | -10167 |
| Results for DeepSeek-R1-Distill-Qwen-7B showing scalability of the approach. | ||||
| AIME 2024 | Accuracy (%) | 53.1 | 58.3 | +5.2 |
| AIME 2024 | Generation Length | 13414 | 5379 | -8035 |
| Comparison against truncation baseline on MATH500 using 1.5B model. | ||||
| MATH500 | Accuracy (%) | 77.7 | 84.2 | +6.5 |
Experiment Figures
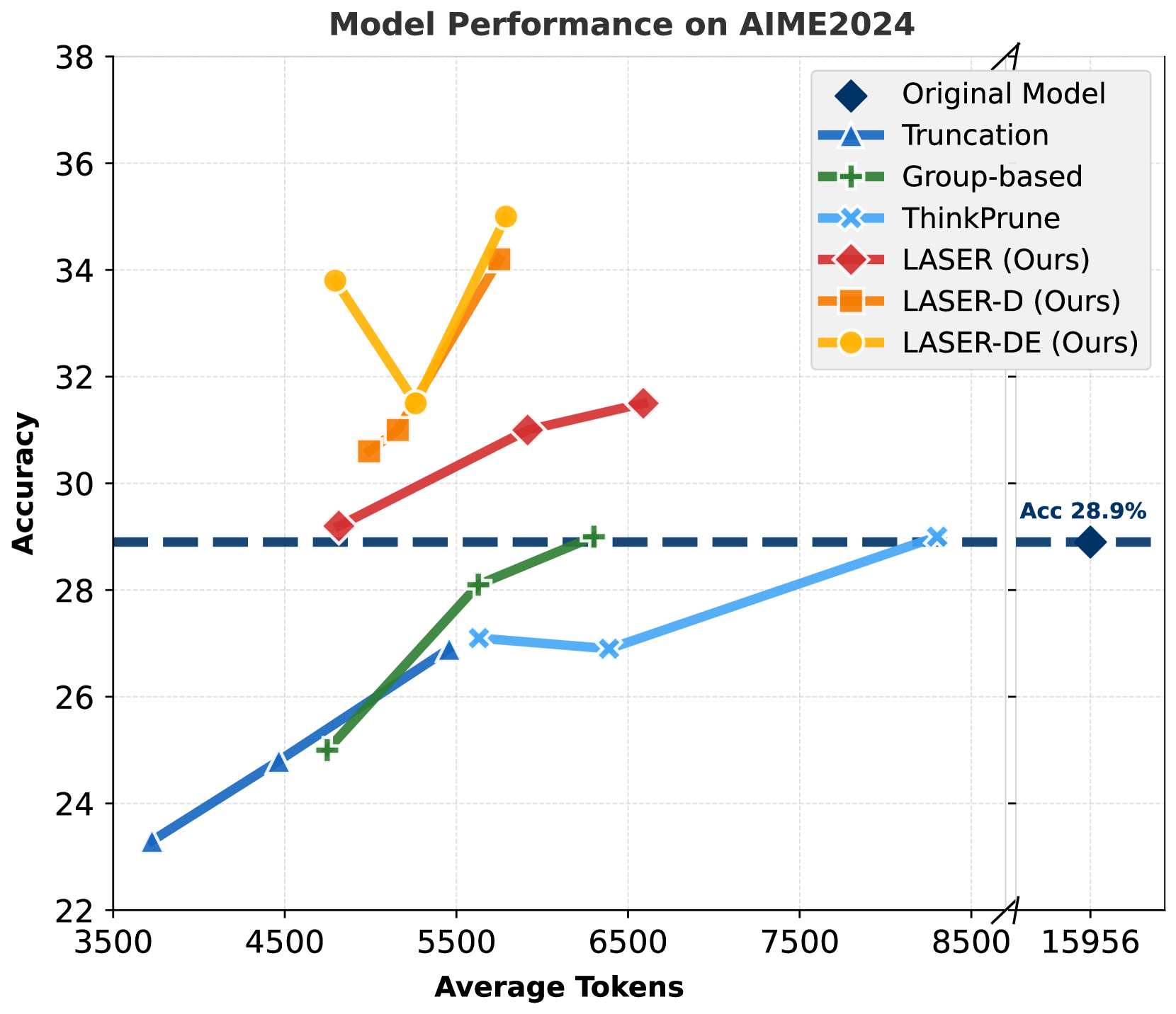
Pareto-optimal frontiers (Accuracy vs Token Usage) for different methods on DeepSeek-R1-Distill-Qwen-1.5B
Evolution of cognitive behaviors (Verification, Backtracking, Subgoal Setting, Enumeration) relative to response length
Main Takeaways
- Dynamic difficulty-aware rewards (Laser-D) allow models to think 'fast' on easy problems and 'slow' on hard ones, optimizing the token budget better than static methods
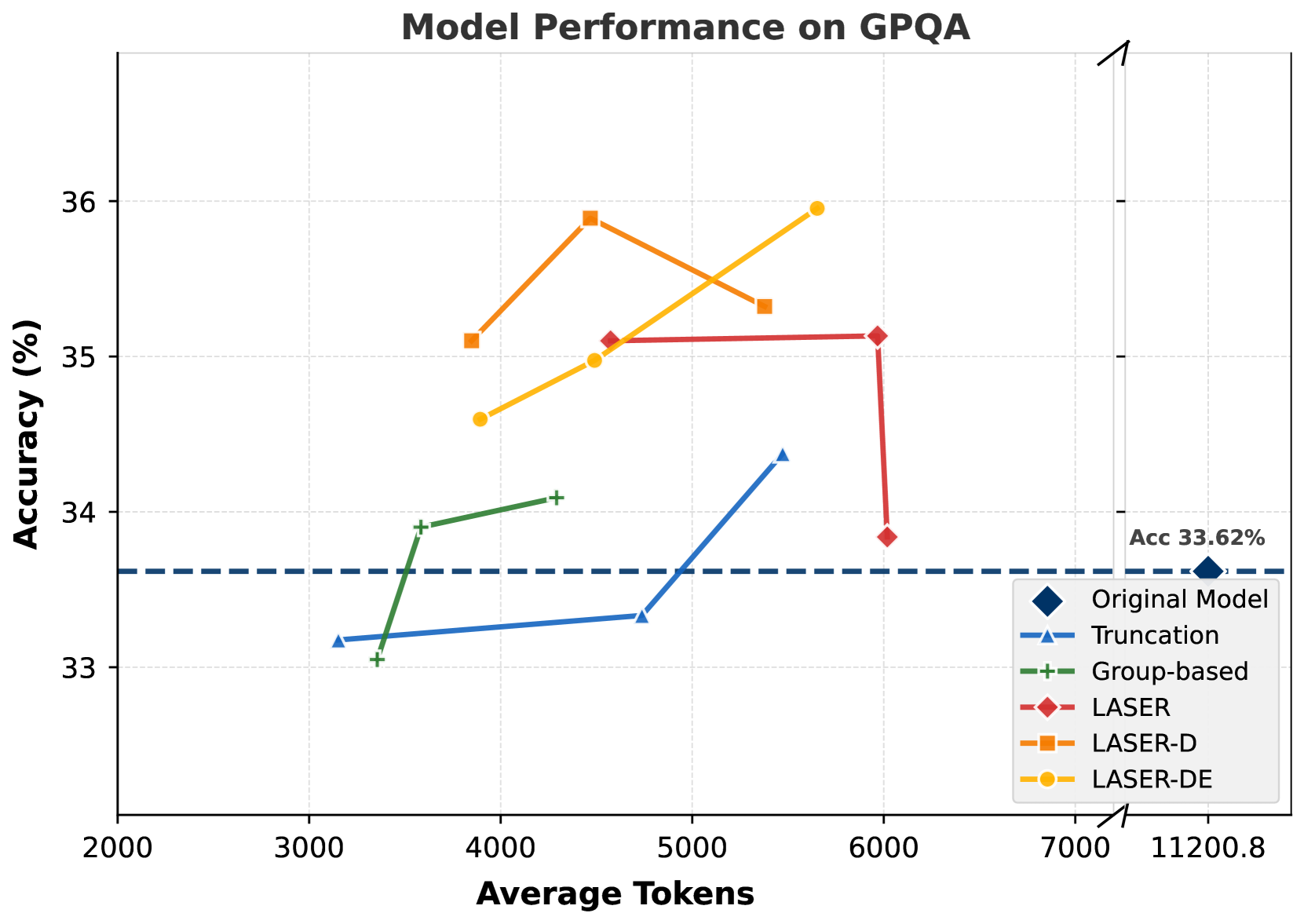
- The approach generalizes to out-of-domain benchmarks (GPQA, LSAT, MMLU) without degradation, showing robust reasoning improvements
- Analysis of reasoning patterns shows a reduction in 'Backtracking' behaviors (recheck, rethink) while preserving constructive 'Subgoal Setting' behaviors
- Simple truncation is effective for efficiency but disproportionately hurts performance on hard tasks (AIME) where long reasoning is actually needed