📝 Paper Summary
LLM Reasoning
Reinforcement Learning from AI Feedback (RLAIF)
ReST-MCTS∗ is a self-training framework that uses tree search and estimated process rewards to automatically generate high-quality reasoning traces and per-step value labels for refining LLM reasoning.
Core Problem
Existing self-training methods rely on final-answer correctness, often keeping traces with wrong reasoning but correct answers (false positives), while training per-step process verifiers typically requires expensive human annotation.
Why it matters:
- False positive reasoning traces (correct answer, wrong logic) degrade model performance on complex tasks
- Manual annotation for Process Reward Models (PRMs) is unscalable, limiting the ability to verify intermediate reasoning steps
- Sparse rewards (only at the end) make credit assignment difficult for long reasoning chains
Concrete Example:
An LLM might solve a math problem by making two calculation errors that cancel each other out, arriving at the correct final number. Standard self-training (like STaR) treats this trace as 'correct' training data, teaching the model bad math. ReST-MCTS∗ detects the low probability of the intermediate steps leading to a correct answer and filters it out.
Key Novelty
Auto-labeled Process Rewards via Tree Search Statistics
- Uses MCTS∗ (a modified Monte Carlo Tree Search) to explore many reasoning paths; the probability of a partial step leading to a correct answer becomes its 'process reward' label
- Circumvents manual labeling by using these search-derived statistics to train a Process Reward Model (PRM) and a Policy Model in a loop
- Introduces 'reasoning distance' (estimated steps to solution) to weight rewards, prioritizing steps that make progress toward the solution
Architecture
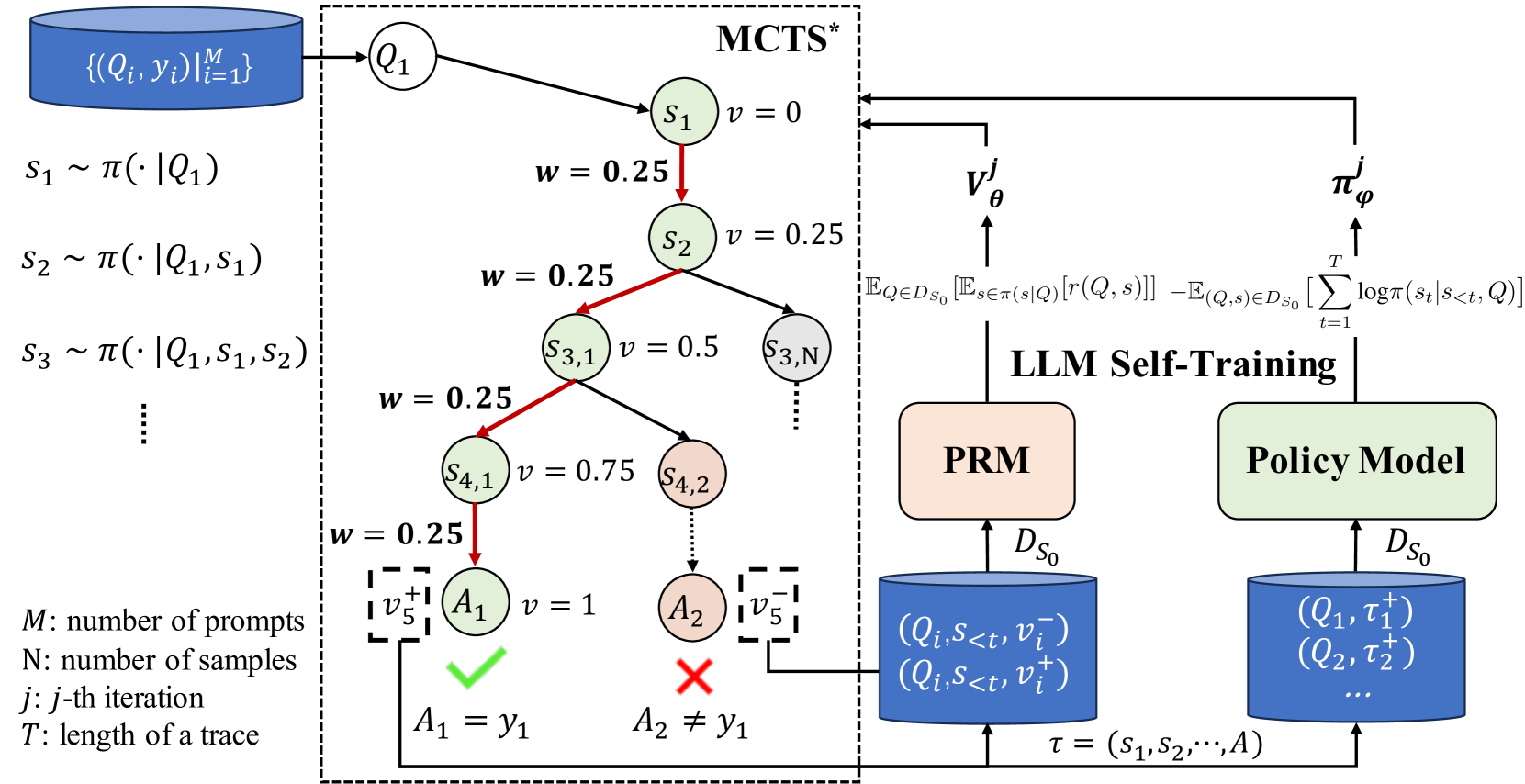
The iterative cycle of ReST-MCTS∗. It shows the interaction between the Policy Model, the Process Reward Model, and the MCTS∗ search process.
Evaluation Highlights
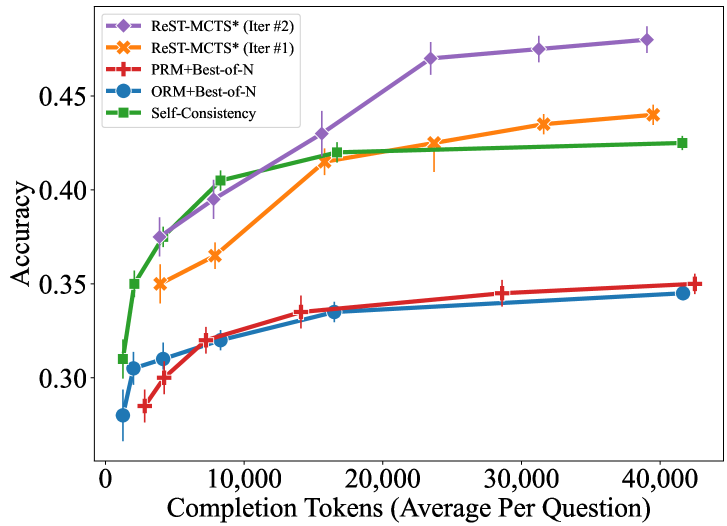
- Outperforms Self-Rewarding LM by +6.2% accuracy on the difficult MATH benchmark
- MCTS∗ search policy achieves 91.2% accuracy on GSM8K, outperforming Tree-of-Thought (85.2%) and Best-of-N (87.8%) given the same budget
- Learned Process Reward Model achieves 72.8% accuracy in selecting correct reasoning steps, surpassing Math-Shepherd (66.8%)
Breakthrough Assessment
8/10
Significantly automates PRM training without human labels, addressing a major bottleneck in reasoning. Strong empirical gains on hard benchmarks like MATH and SciBench.