📝 Paper Summary
Reward Modeling
Reinforcement Learning from Human Feedback (RLHF)
Model Merging
DogeRM improves reward model performance in specialized domains like math and coding by merging a general-purpose reward model with domain-specific supervised fine-tuned models, avoiding the need for costly domain-specific preference data.
Core Problem
Training reward models (RMs) for specific domains like math or coding typically requires expensive, expert-annotated paired preference data, which is scarce and costly to collect.
Why it matters:
- Standard RMs trained on general preference data often lack the deep domain knowledge needed to accurately evaluate specialized outputs (e.g., complex code or math proofs)
- Collecting domain-specific preference pairs (chosen vs. rejected) is significantly harder and more expensive than collecting standard supervised fine-tuning (SFT) data
- Current methods rely on heavy fine-tuning, whereas high-quality domain SFT models are readily available and underutilized for reward signal improvement
Concrete Example:
A general reward model might fail to distinguish a subtle bug in a code solution from a correct one because it wasn't trained on enough coding examples. DogeRM merges this RM with a model specifically fine-tuned on code, injecting the necessary expertise to identify the correct solution without needing new preference pairs.
Key Novelty
Domain knowledge merged Reward Model (DogeRM)
- Merges the weights of a general-purpose Reward Model (trained on standard preference data) with a Domain-Specific SFT Model (trained on math/code) initialized from the same base
- Uses a disjoint merging strategy: separates the model into embedding, transformer, and head layers, applying weighted averaging to shared components while preserving the RM's regression head
- Adjusts the interpolation weight (lambda) based on a small validation set to balance general alignment capability with specific domain expertise
Architecture
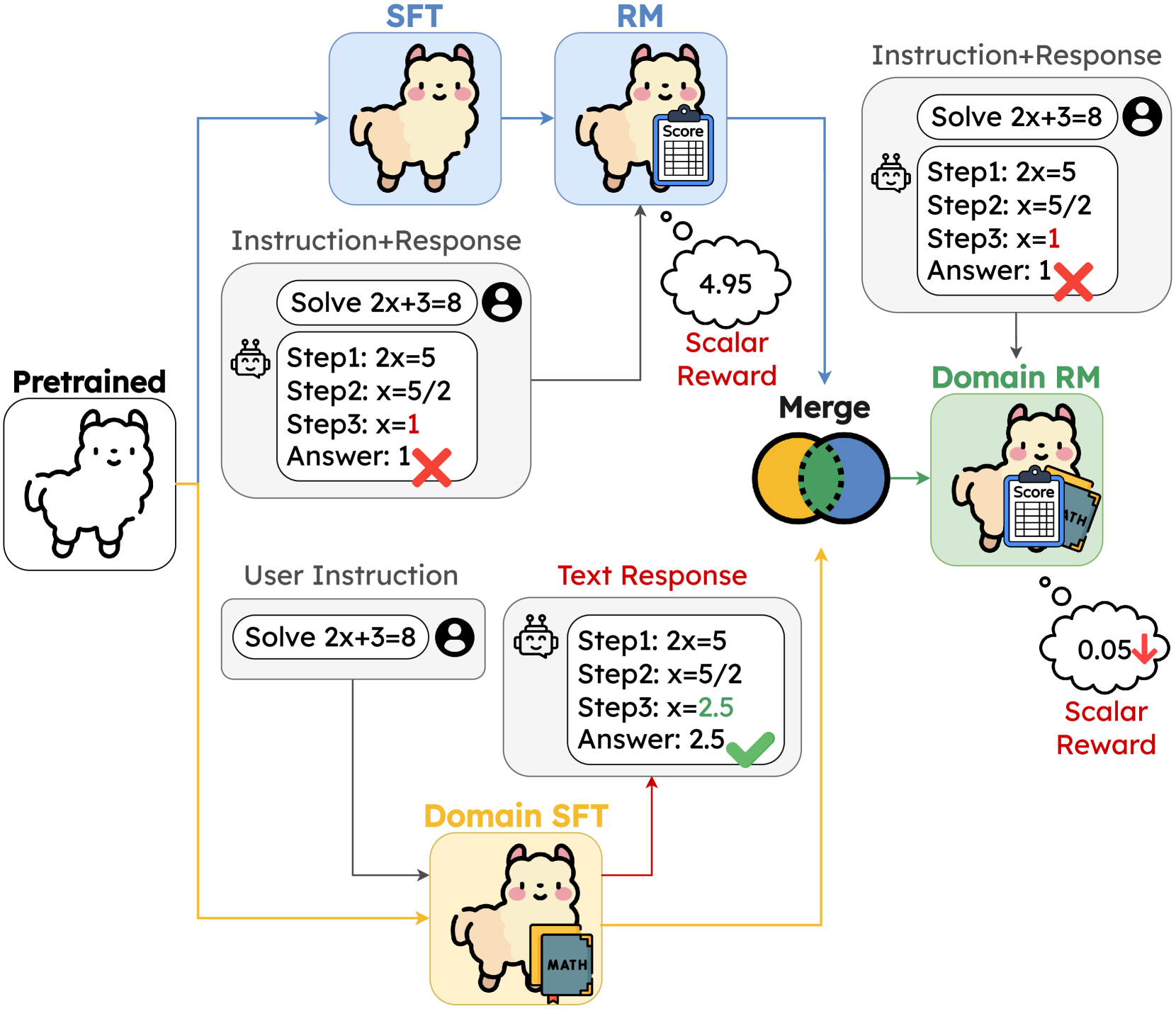
Illustration of the DogeRM framework. It shows the merging of a 'General Preference RM' and a 'Domain-Specific SFT Model' (e.g., Math/Code) into a single 'Domain knowledge merged RM'.
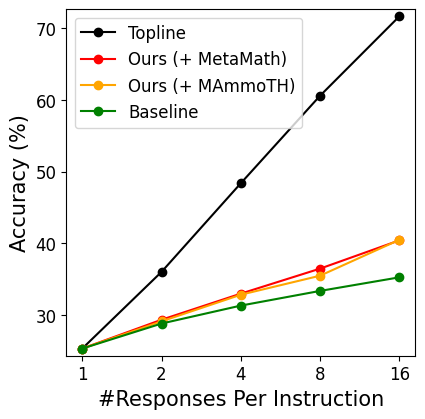
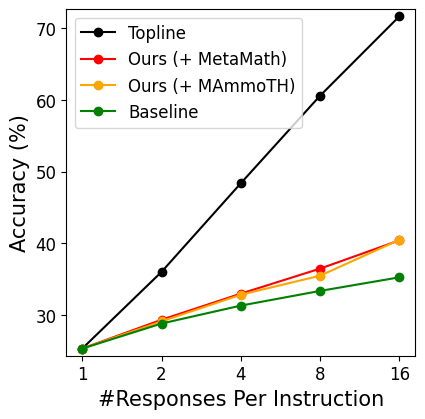
Evaluation Highlights
- +17.0% accuracy improvement on the RewardBench Math subset when merging LLaMA-2 RM with MAmmoTH-7B
- +11.4% accuracy improvement on RewardBench Math when merging with MetaMath-7B
- +6.0% accuracy improvement on Auto-J Eval Code subset when merging with a custom Code Model
Breakthrough Assessment
7/10
A simple yet effective method that addresses a major bottleneck in RLHF (scarcity of domain preference data) by leveraging abundant SFT models. The gains are significant, though the technique itself (linear merging) is standard.