📝 Paper Summary
Process Reward Models (PRMs)
Test-Time Scaling (TTS)
Mathematical Reasoning
GenPRM redefines process supervision as a generative reasoning task enabling test-time compute scaling via verification-specific Chain-of-Thought and code execution, allowing smaller models to outperform larger discriminative baselines.
Core Problem
Existing Process Reward Models are trained as discriminative classifiers that output scalar scores, preventing them from leveraging the generative reasoning capabilities of LLMs or scaling compute at test time.
Why it matters:
- Discriminative PRMs have limited process supervision and generalization capabilities compared to generative models.
- Scalar prediction ignores the potential of 'thinking' (reasoning) about why a step is correct or incorrect.
- Current verifiers cannot improve their judgment quality by spending more inference time (test-time scaling), unlike reasoning policies (e.g., o1).
Concrete Example:
In a complex math problem, a standard PRM might assign a score of 0.8 to a step containing a subtle calculation error because it looks superficially correct. A generative PRM would attempt to write code to verify that specific calculation, execute it, find the discrepancy, and output a 'No' judgment.
Key Novelty
Generative Process Reward Model (GenPRM)
- Transforms verification from classification (scalar output) to generation: the model produces Chain-of-Thought reasoning and Python code to verify a step before judging it.
- Uses Relative Progress Estimation (RPE) to label training data, defining a 'correct' step as one that increases the probability of finding the final answer relative to the previous state.
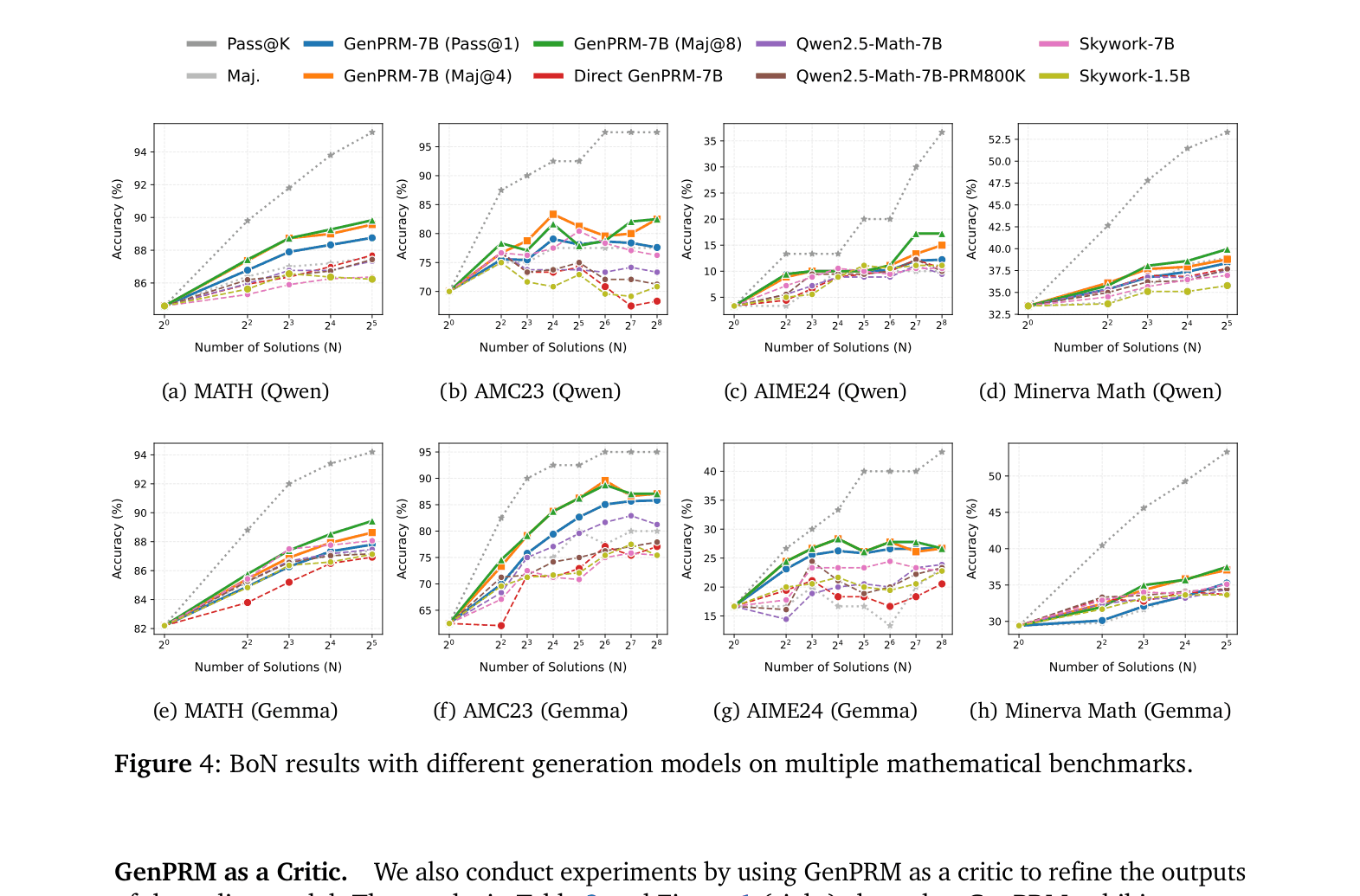
- Enables Test-Time Scaling for the verifier itself: by sampling multiple reasoning/code-verification paths and voting, the verifier's accuracy improves with more compute.
Architecture
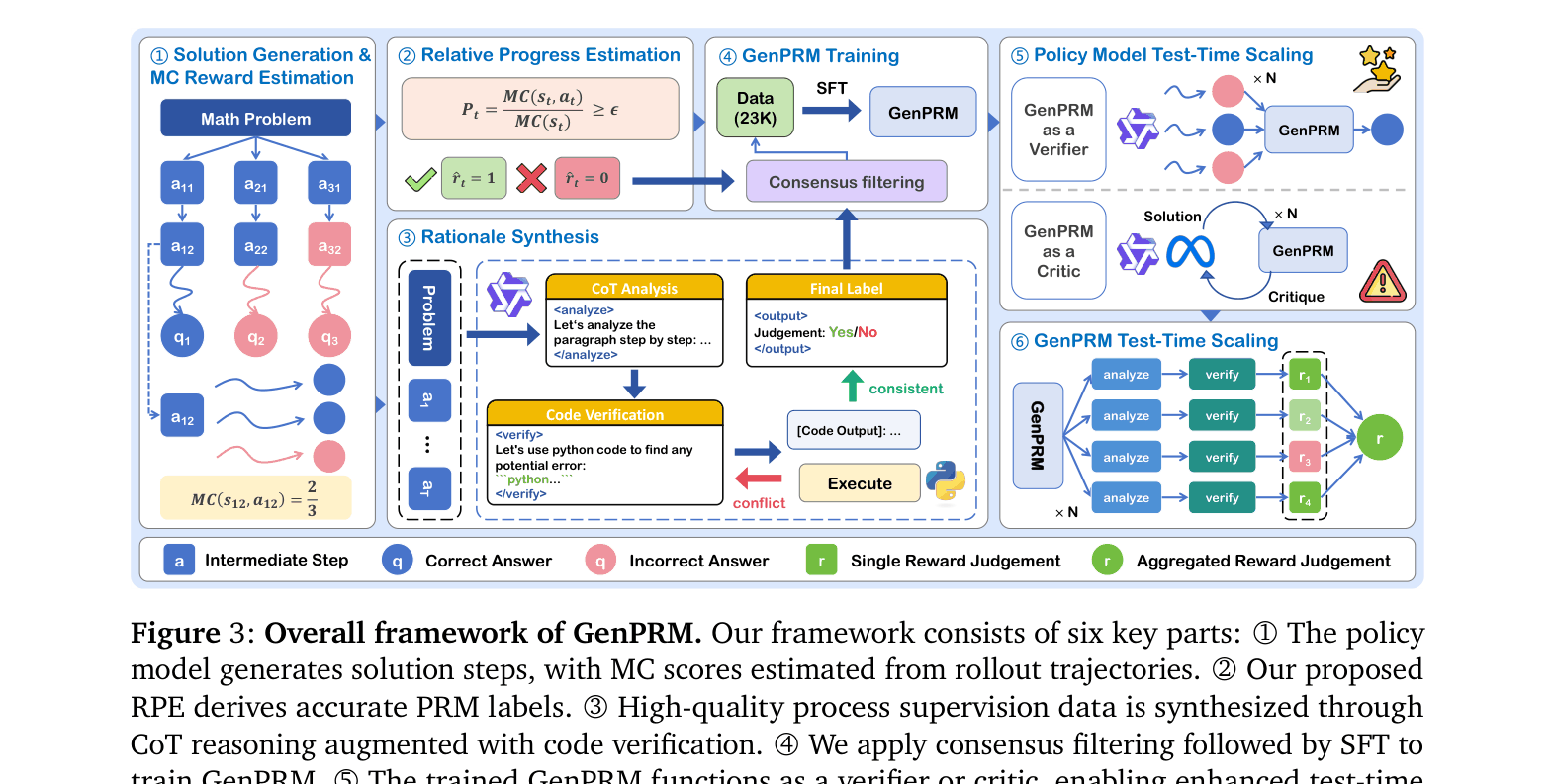
The overall framework of GenPRM including data synthesis, training, and test-time scaling.
Evaluation Highlights
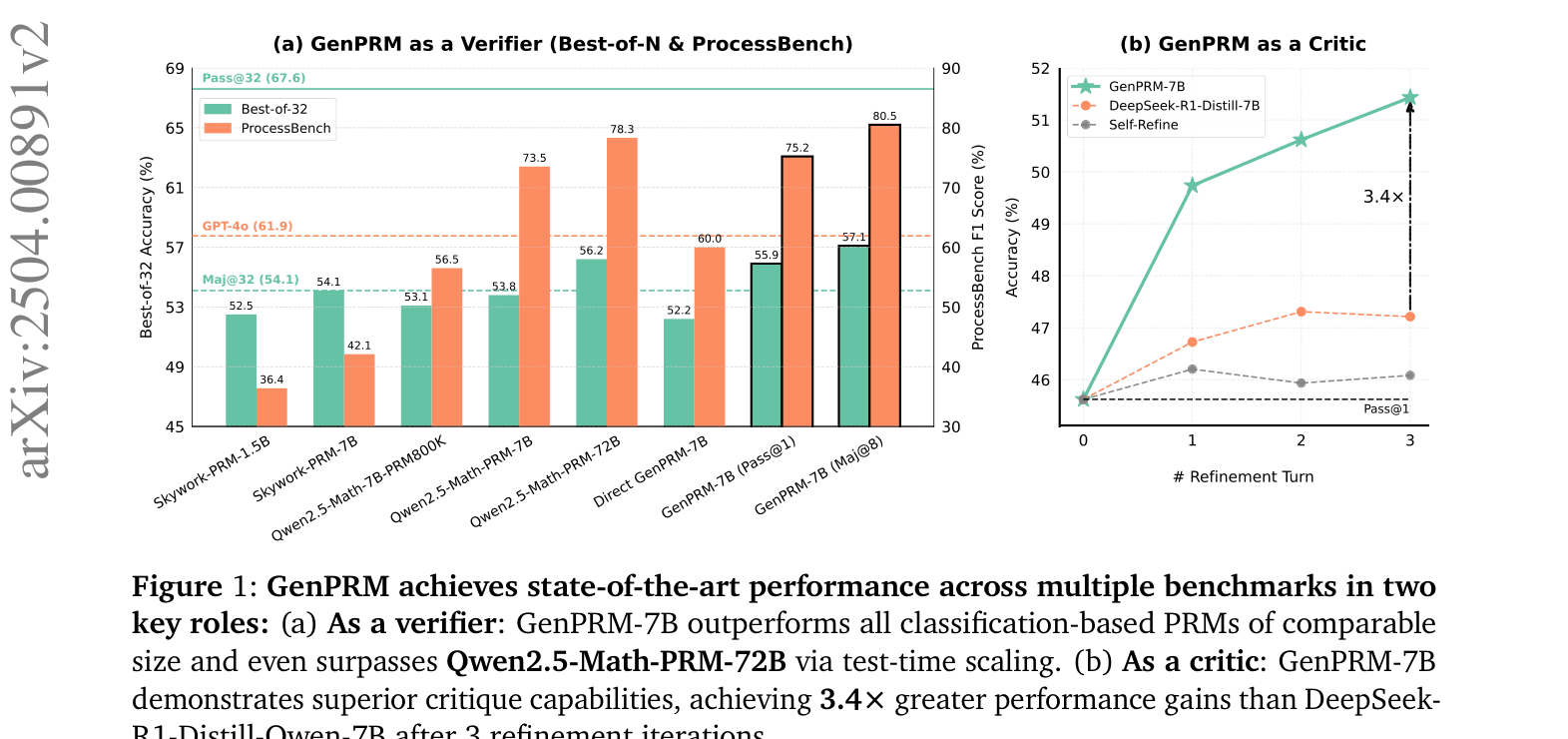
- GenPRM-7B with majority voting (Maj@8) achieves 80.5% F1 on ProcessBench, outperforming the much larger Qwen2.5-Math-PRM-72B (78.3%).
- GenPRM-1.5B (Maj@8) reaches 63.4% on ProcessBench, surpassing the proprietary GPT-4o (61.9%).
- As a critic model, GenPRM-7B improves policy performance on MATH to 55.4% (Turn 3), significantly higher than DeepSeek-R1-Distill-7B (51.7%).
Breakthrough Assessment
9/10
Significant paradigm shift from discriminative to generative verification. Demonstrates that scaling verification compute allows small models to beat 10x larger models and GPT-4o. Highly relevant to current 'reasoning model' trends.