📝 Paper Summary
LLM-driven Reward Design
Automated Reinforcement Learning
Reward Engineering
CARD is an automated framework that uses a Coder-Evaluator architecture to iteratively design and refine RL reward functions using dynamic feedback and trajectory preferences without human intervention.
Core Problem
Manually designing reward functions for RL is difficult and expensive, while existing LLM-based methods suffer from hallucinations or require extensive human feedback and repetitive, costly RL training loops.
Why it matters:
- Real-world tasks often lack well-defined reward functions, blocking RL adoption.
- Inverse RL requires expensive expert demonstrations which are hard to obtain.
- Existing LLM methods waste tokens on parallel sampling or require humans to manually correct code or analyze trajectories.
Concrete Example:
In a robotic manipulation task, an LLM might generate a reward function that compiles but fails to encourage the correct movement. Previous methods would re-run the full RL training to find this out, or ask a human to debug. CARD detects the issue via trajectory analysis or preference checks before full training commits.
Key Novelty
Coder-Evaluator Reward Design (CARD)
- Splits the design process into a Coder (generates/refines code) and an Evaluator (analyzes performance), simulating a developer-tester loop.
- Introduces Trajectory Preference Evaluation (TPE) to filter poor reward functions by checking if successful trajectories actually get higher rewards than failed ones, skipping unnecessary RL training.
Architecture
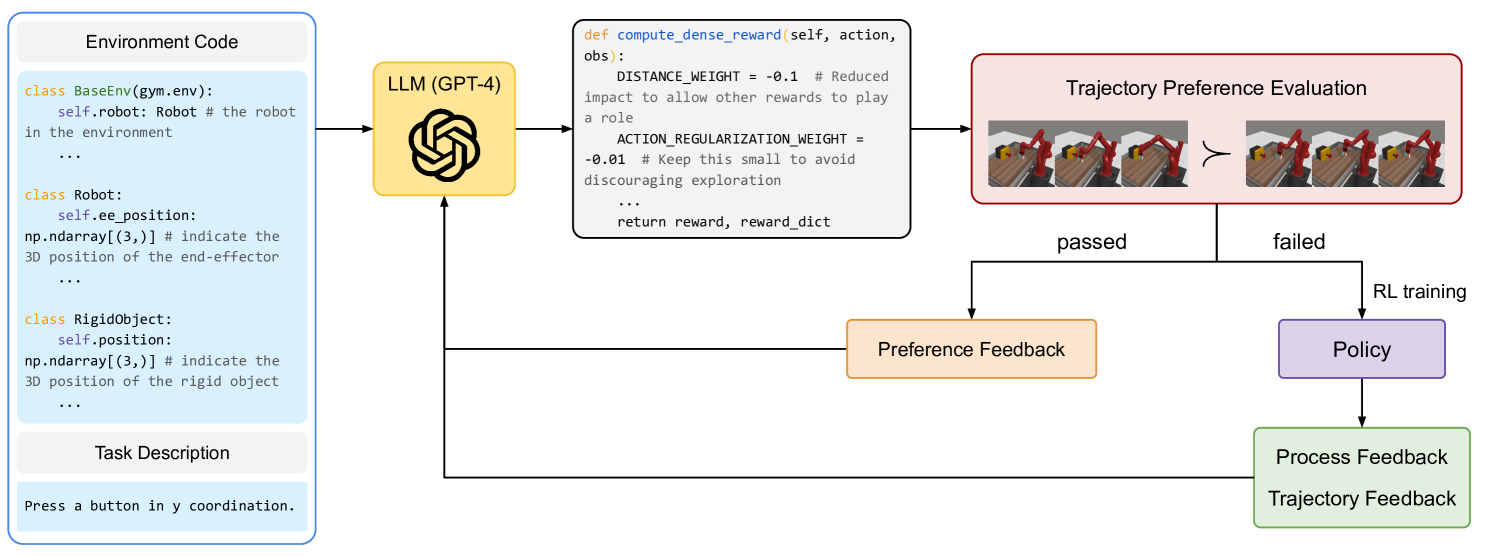
The overall CARD framework pipeline, illustrating the interaction between the Coder and Evaluator.
Evaluation Highlights
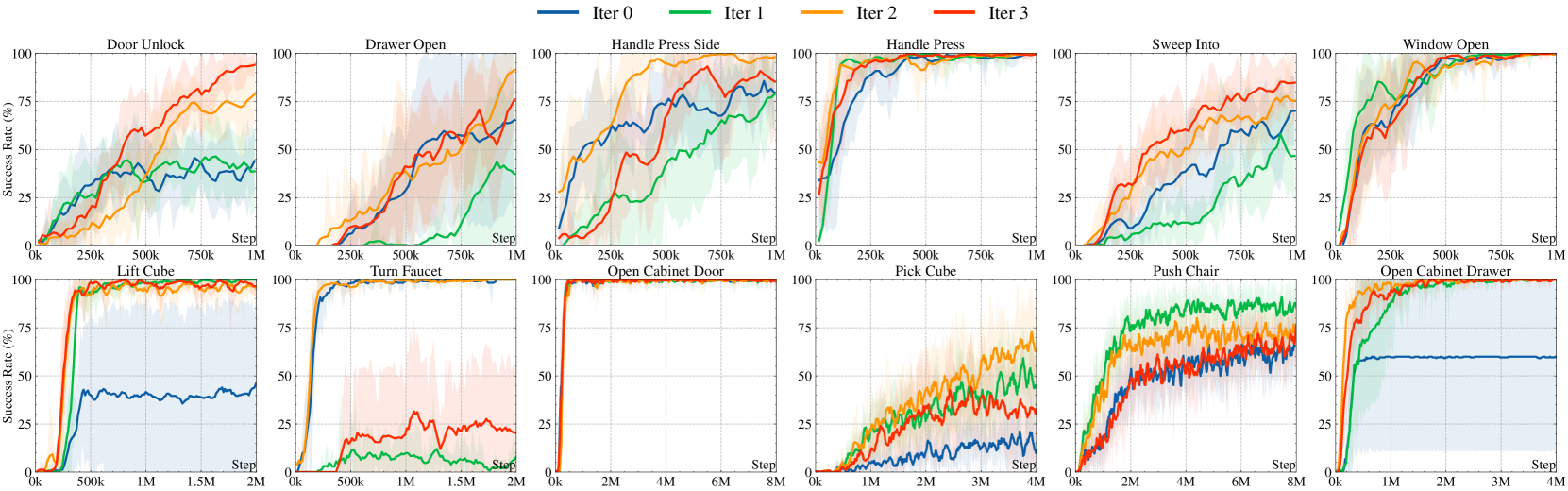
- Surpasses human oracle performance on 3 tasks (e.g., Push-Wall, Pick-Place) in Meta-World and ManiSkill2.
- Achieves better or comparable performance to expert-designed rewards on 10 out of 12 tested tasks.
- Significantly reduces token consumption and training time compared to Eureka (SOTA baseline) by avoiding parallel sampling and unnecessary training runs.
Breakthrough Assessment
8/10
Strong methodological contribution with the TPE mechanism which efficiently prunes the search space, addressing the major bottleneck of computational cost in LLM-based RL.