📝 Paper Summary
Video Generation
Consistency Models
T2V-Turbo accelerates high-quality video generation by integrating mixed image and video reward feedback directly into the single-step consistency distillation process, bypassing iterative backpropagation memory costs.
Core Problem
Diffusion-based video models suffer from slow iterative sampling, while faster Consistency Models (CMs) face a quality bottleneck limited by their teacher models and reduced step counts.
Why it matters:
- Slow inference prevents real-time applications of high-quality video generation models
- Existing open-source models trained on web-scale data often fail to align with human aesthetic preferences and text prompts
- Previous reward-finetuning methods like InstructVideo are memory-prohibitive due to backpropagating gradients through long sampling chains
Concrete Example:
A standard diffusion model requires 50 iterative steps to generate a coherent video, taking seconds to minutes. Existing distillation methods reduce this to 4 steps but produce blurry or temporally inconsistent results because they only mimic the teacher model without incorporating direct human preference feedback.
Key Novelty
Mixed Reward Feedback in Consistency Distillation
- Integrates feedback from both Image-Text (spatial) and Video-Text (temporal) reward models directly into the distillation loss
- Optimizes the single-step generation produced during consistency distillation, avoiding the high memory cost of backpropagating through iterative sampling steps
Architecture
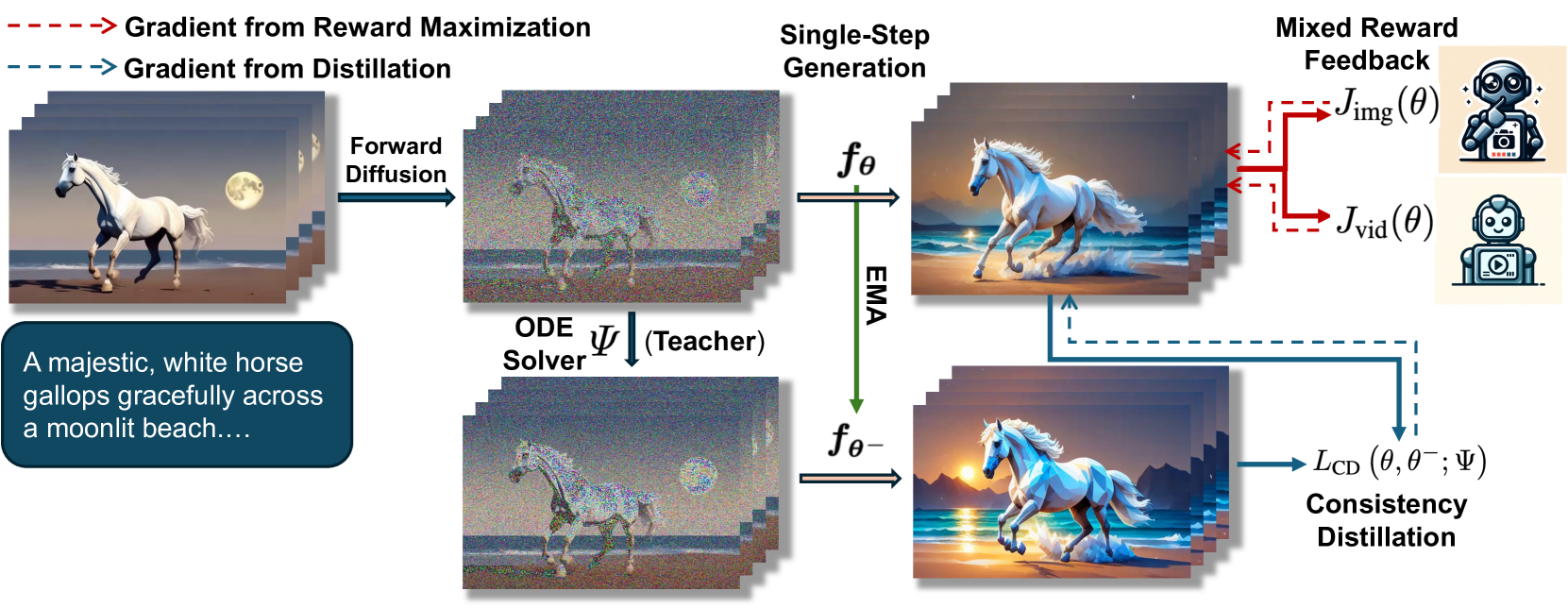
The training pipeline showing how reward feedback is integrated into Consistency Distillation
Evaluation Highlights
- Achieves >10x inference acceleration (4 steps vs 50 steps) while improving quality over teacher models
- 4-step generations surpass proprietary systems Gen-2 and Pika on the VBench evaluation benchmark
- Human evaluators prefer 4-step T2V-Turbo videos over 50-step generations from the original teacher models (VideoCrafter2 and ModelScopeT2V)
Breakthrough Assessment
8/10
Successfully combines speed (consistency models) with high quality (reward feedback) in a memory-efficient way, outperforming proprietary commercial baselines with significantly fewer inference steps.