📝 Paper Summary
End-to-End Autonomous Driving
Vision-Language-Action (VLA) Models
Reinforcement Learning
IRL-VLA trains an autonomous driving agent using a learned Reward World Model (RWM) instead of a heavy simulator, enabling efficient closed-loop reinforcement learning to improve safety and comfort.
Core Problem
Existing VLA models rely on open-loop imitation learning, which merely copies dataset behaviors and fails to generalize, while closed-loop RL is hindered by computationally expensive simulators and Sim2Real gaps.
Why it matters:
- Imitation learning limits agents to the quality of recorded data, preventing them from learning how to recover from mistakes or handle rare scenarios
- High-fidelity simulators are too slow for efficient large-scale reinforcement learning and often do not perfectly reflect real-world sensor noise (domain gap)
Concrete Example:
In a long-tail scenario where a human driver makes a slight error, an imitation-trained model might copy the error or fail to recover. Standard RL could fix this but requires rendering millions of simulation frames. IRL-VLA predicts the 'crash' penalty directly via a neural network, skipping the heavy rendering.
Key Novelty
Reward World Model (RWM) via Inverse Reinforcement Learning
- Instead of using a physics simulator to calculate rewards (like collisions), the system trains a lightweight neural network (RWM) to predict these scores directly from sensor data and trajectories
- This RWM serves as a differentiable, fast 'virtual environment' that provides feedback to the driving agent during Reinforcement Learning, bypassing the need for heavy sensor simulation
Architecture
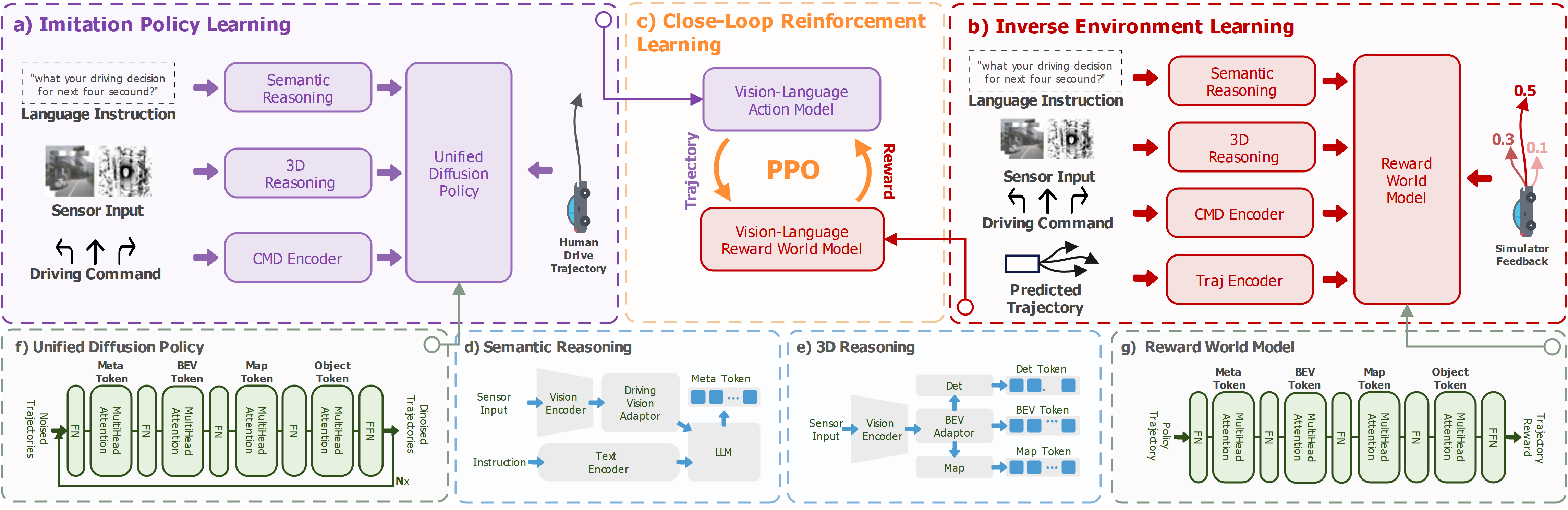
The overall IRL-VLA framework, comprising the VLA agent architecture, the Reward World Model (RWM), and the RL training loop.
Evaluation Highlights
- Achieves 45.0 EDPMS (Ego-Pseudo Driving Metric System) score on the NAVSIM v2 benchmark
- Secured 1st runner-up position in the CVPR 2025 Autonomous Grand Challenge
- Demonstrates capability to optimize multi-objective metrics (safety, comfort, traffic rules) simultaneously via the Reward World Model
Breakthrough Assessment
8/10
Proposes a novel paradigm of replacing simulators with learned reward models for VLA training, directly addressing the scalability bottleneck of RL in autonomous driving. High benchmark performance confirms viability.