📝 Paper Summary
LLM Alignment
Reinforcement Learning from Human Feedback (RLHF)
Generative Model Fine-tuning
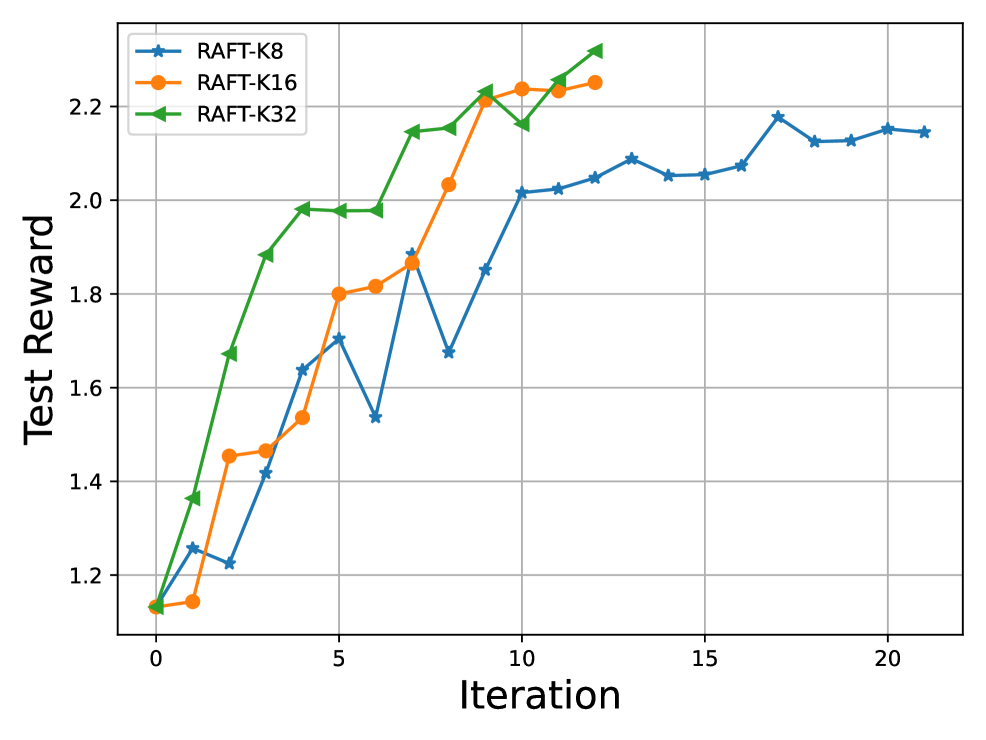
RAFT aligns generative models by iteratively generating samples, filtering them via a reward model, and fine-tuning on the high-reward subset, offering a stable alternative to PPO.
Core Problem
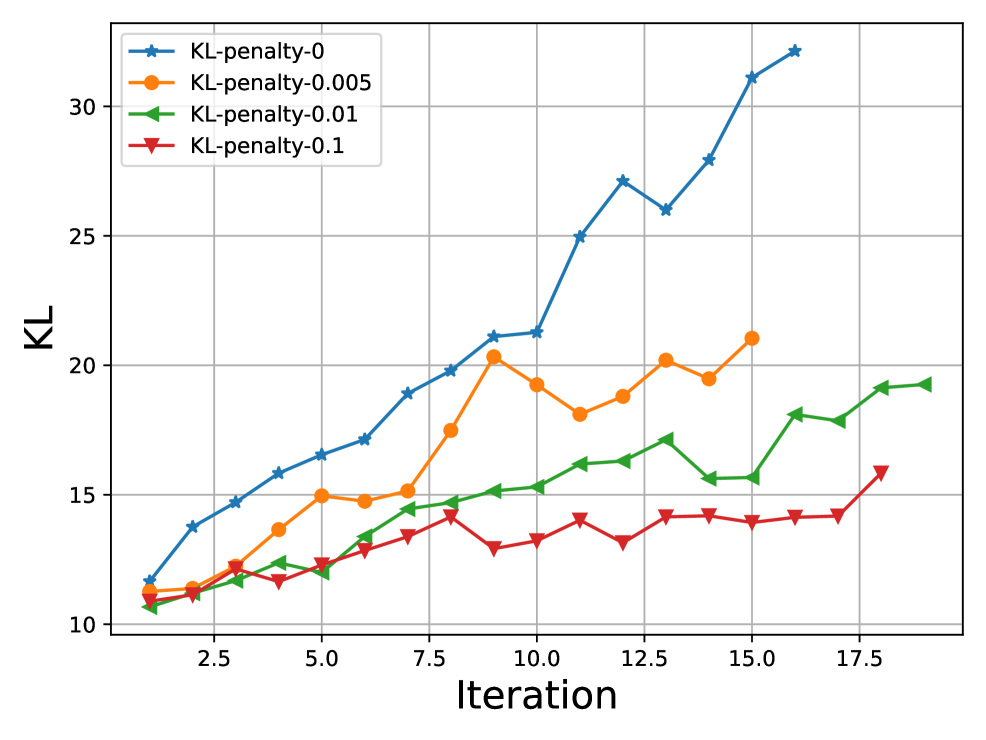
Standard RLHF using PPO is notoriously unstable, inefficient, and memory-intensive, requiring four simultaneous models during training.
Why it matters:
- PPO's 'trial-and-error' learning is less stable and efficient than supervised learning
- Loading multiple models (actor, critic, ref, reward) causes heavy memory burden
- Pre-determined offline datasets for SFT often lack sufficient coverage to compete with optimal policies
Concrete Example:
In standard PPO, a model must explore actions and update via complex gradients while maintaining a critic and reference model. If the reward signal is noisy, PPO training often collapses or hacks the reward, whereas RAFT simply filters out the bad samples before training.
Key Novelty
Iterative Reward-Ranked Fine-Tuning
- Decouples data generation from model training: the model generates candidate responses, a reward model ranks them, and only the top candidates are kept.
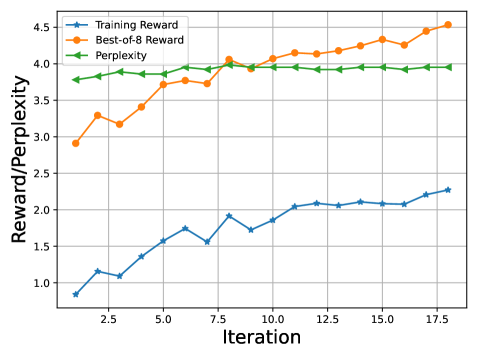
- Uses standard Supervised Fine-Tuning (SFT) on these self-generated 'best-of-K' samples, which is more stable than policy gradient methods.
- Iterates this process: the improved model generates better data in the next round, progressively approximating the optimal policy.
Architecture
The three-step iterative process of RAFT: Data Collection, Data Ranking, and Model Fine-tuning.
Evaluation Highlights
- RAFT outperforms PPO on the HH-RLHF dataset, achieving a reward of -1.09 vs -1.25 (lower is better in this specific reward scale context, or higher if normalized - paper shows RAFT consistently higher reward curves).
- In GPT-4 evaluation, RAFT wins 57.0% of the time against the PPO baseline on the HH-RLHF test set.
- Achieves superior performance on diffusion models (Stable Diffusion) for aesthetic improvement, raising aesthetic score from 4.72 to 5.60.
Breakthrough Assessment
8/10
Provides a highly effective, simpler, and more stable alternative to PPO for RLHF. The method (essentially iterative rejection sampling SFT) has since become a standard technique (e.g., in Llama-2/3 alignment) due to its robustness.