📝 Paper Summary
LLM Alignment
Reward Modeling
Direct Preference Optimization (DPO)
The implicit reward model defined by DPO generalizes significantly worse to out-of-distribution prompts and responses than explicitly trained reward models, motivating the use of explicit rewards in iterative alignment.
Core Problem
DPO aligns models without an explicit reward model (EXRM), but it is unclear if the implicit reward model (DPORM) learned during this process generalizes well to unseen data.
Why it matters:
- Poor reward generalization leads to over-optimization and reward hacking when the policy model encounters OOD data during training
- Iterative alignment methods (like Iterative DPO) rely on the reward model to label new model generations; if the reward model fails on OOD data, the entire alignment process degrades
Concrete Example:
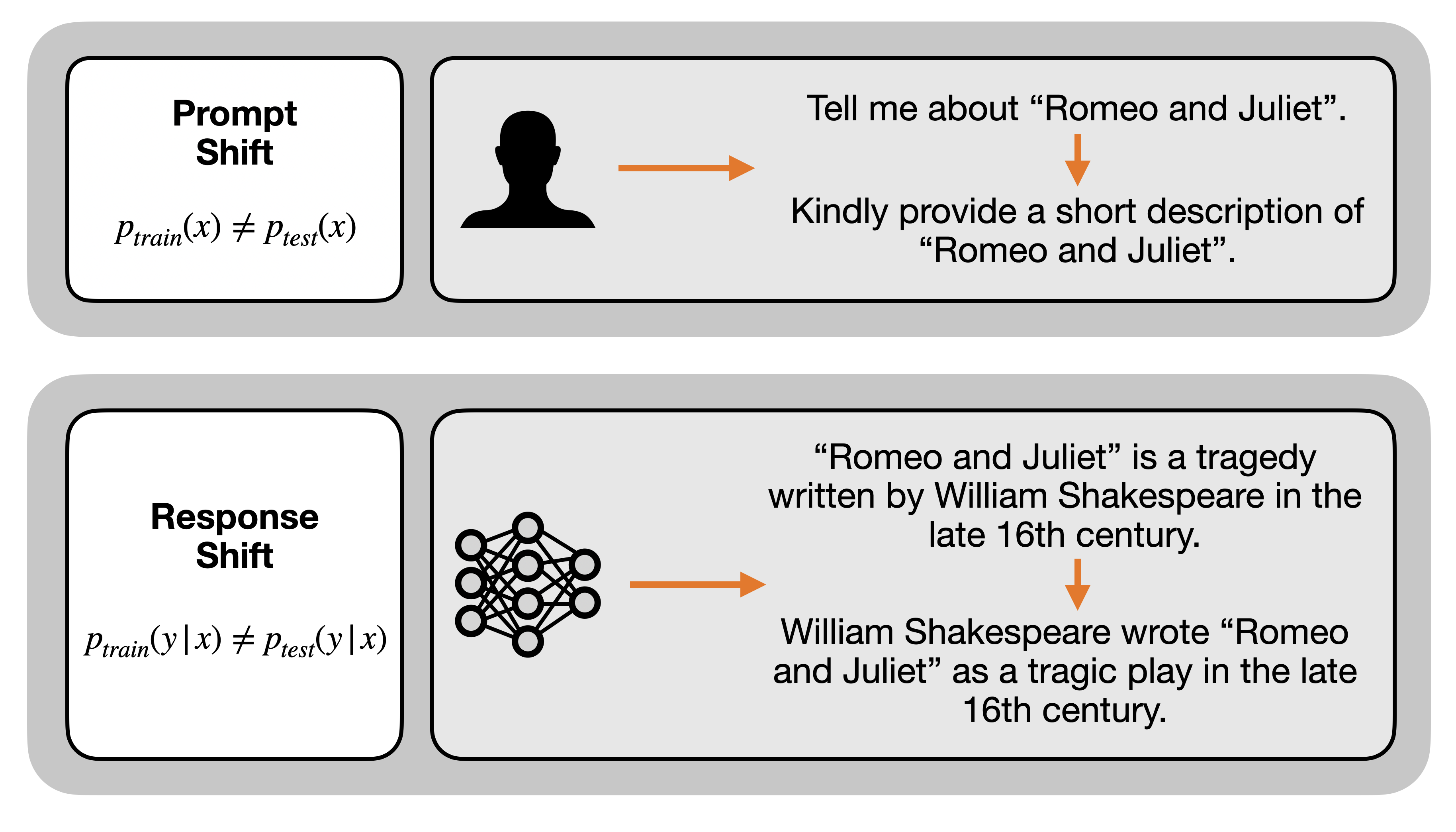
When a reward model trained on UltraFeedBack is used to evaluate responses from a different dataset like Reddit Summarization (Prompt Shift), DPORM's accuracy drops significantly compared to EXRM, potentially mislabeling preferred summaries.
Key Novelty
Systematic Generalization Audit of DPO vs. Explicit Reward Models
- Conducts extensive experiments comparing explicit reward models (EXRM) against DPO's implicit reward (DPORM) across 5 train-test shifts and 3 model scales
- Isolates specific types of distribution shifts: Prompt Shift (different domains) and Response Shift (different generator models)
- Demonstrates that while DPORM fits training data well, it lacks the robustness of EXRM, justifying hybrid approaches like Iterative DPO with explicit rewards
Architecture
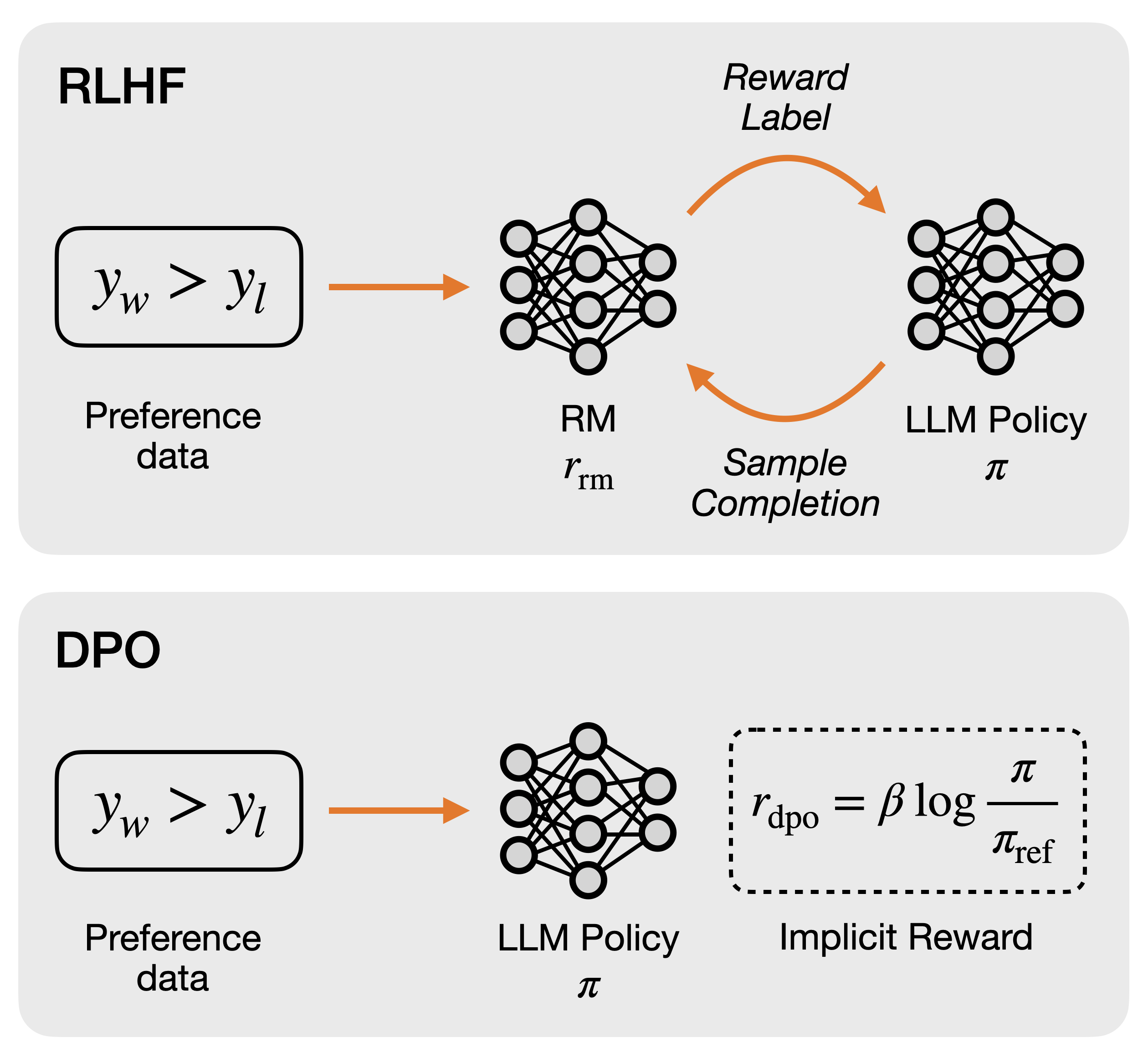
Overview of the RLHF and DPO pipelines, contrasting Explicit Reward Model training (RLHF) with Implicit Reward formulation (DPO).
Evaluation Highlights
- Across 5 out-of-distribution settings, DPORM suffers a mean accuracy drop of 3% and a maximum drop of 7% compared to EXRM
- EXRM achieves a higher win rate (accuracy > 50%) than DPORM in over 90% of out-of-distribution experiments
- In iterative DPO alignment, using an EXRM for labeling results in a 10.3% higher win rate on AlpacaEval compared to using DPORM (57.8% vs 47.5%)
Breakthrough Assessment
4/10
This is a rigorous empirical analysis rather than a new method. It provides crucial insights into the limitations of DPO, challenging the assumption that implicit rewards are sufficient for robust alignment.