📊 Experiments & Results
Evaluation Setup
Fine-tuning Stable Diffusion on specific tasks (Hand/Body generation, Safety) and measuring improvement via human evaluation and proxy metrics.
Benchmarks:
- Deformity Correction (Image Quality / Anatomy) [New]
- Safety Alignment (Harmlessness / NSFW filtering) [New]
- Prompt-Image Alignment (General text-to-image alignment)
Metrics:
- Human Preference Win Rate
- Abnormal Rate (for hands/bodies)
- Unsafe Rate (for NSFW)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| D3PO significantly reduces image defects compared to the base Stable Diffusion model. | ||||
| Hand Generation | Abnormal Rate | 28.4 | 13.9 | -14.5 |
| Body Generation | Abnormal Rate | 34.4 | 17.4 | -17.0 |
| NSFW Prompts | Unsafe Rate | 25.0 | 3.0 | -22.0 |
| D3PO achieves high win rates against the base model in human evaluations. | ||||
| General Preference | Win Rate vs SD v1.4 | 50.0 | 70.3 | +20.3 |
Experiment Figures
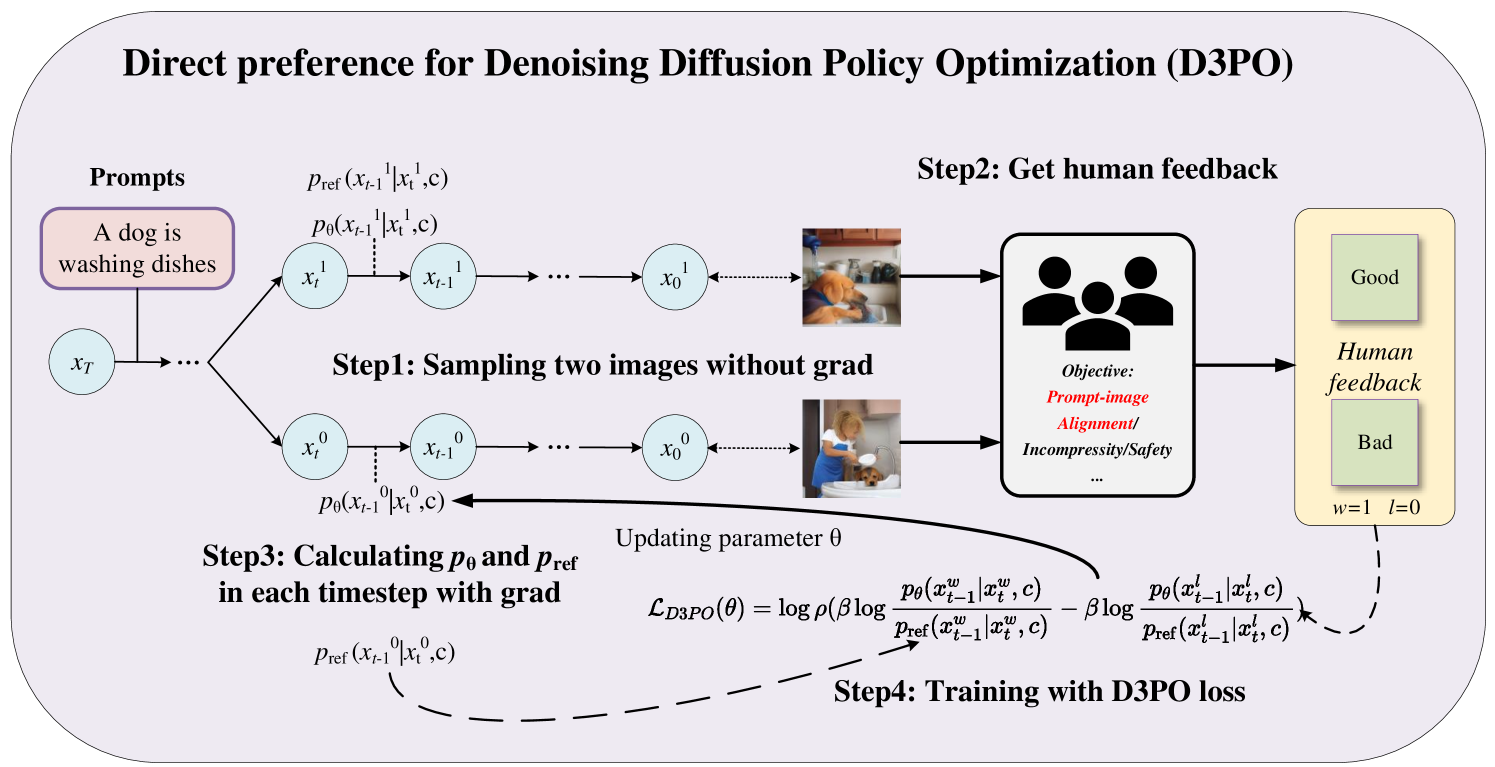
Qualitative comparison of generated images (hands and full-body shots) before and after fine-tuning.
Main Takeaways
- D3PO effectively fine-tunes diffusion models to reduce specific defects (hands, bodies) and improve safety without needing a separate reward model.
- The method is highly efficient, requiring only 20-40 minutes on a single A800 GPU to achieve these results.
- Theoretical analysis confirms that direct preference optimization in the MDP setting acts as an optimal reward model guiding the policy.
- The approach overcomes the memory bottleneck that prevents applying standard LLM-DPO to diffusion models.