📊 Experiments & Results
Evaluation Setup
Verification of mathematical reasoning trajectories generated by LLMs
Benchmarks:
- MATH500 (Mathematical reasoning)
Metrics:
- Best-of-N Verification Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| MATH500 | Verification Accuracy (Best-of-N) | 39.8 | 51.4 | +11.6 |
Experiment Figures
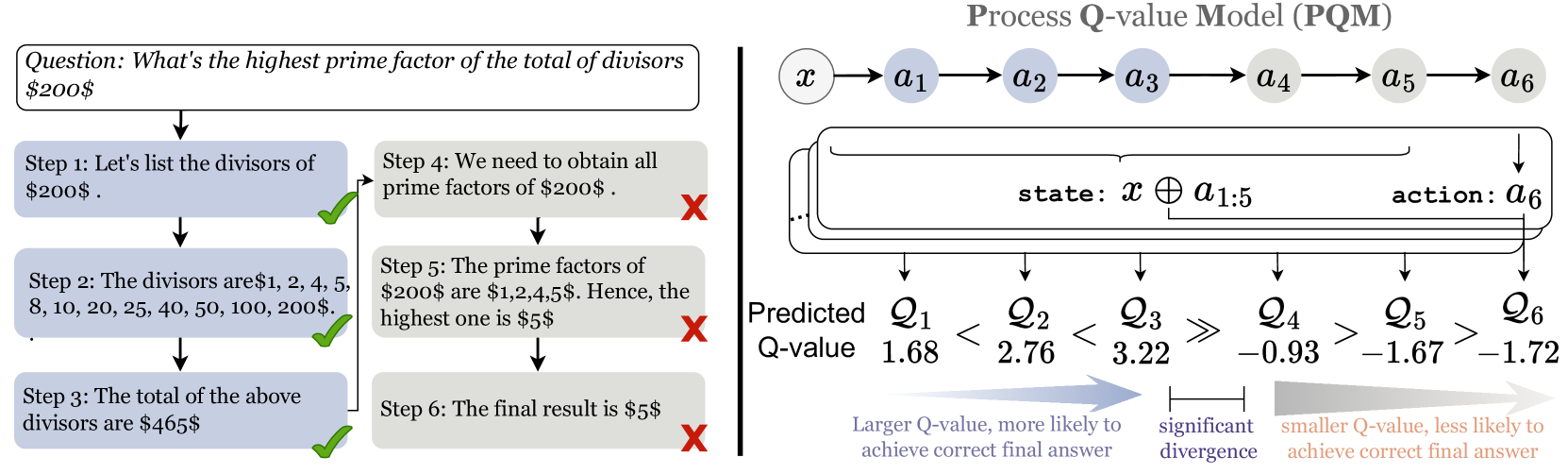
Conceptual illustration of Q-value dynamics (ascending for correct steps, descending for wrong steps)
Main Takeaways
- PQM significantly outperforms classification-based PRMs in verification tasks (+11.6% on MATH500), indicating that ranking based on Q-values is superior to independent correctness classification.
- The theoretical framework successfully predicts the behavior of optimal value functions: Q-values rise as correct steps accumulate and fall when incorrect steps are taken.
- Framing PRM within a formal MDP provides a theoretical basis lacking in previous heuristic classification approaches.