📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Mechanistic Interpretability
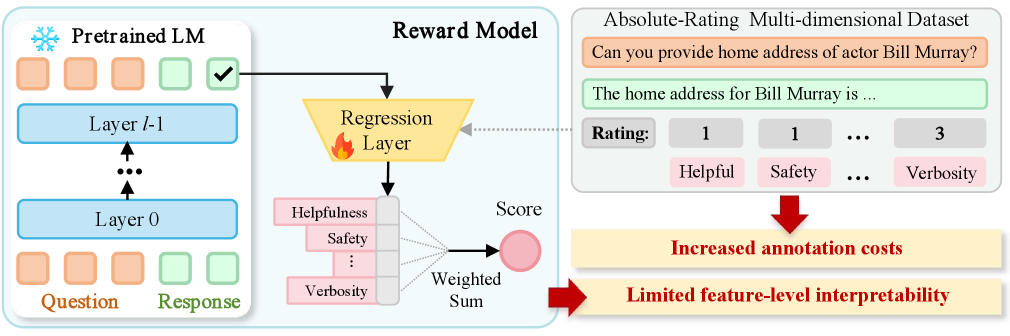
Reward Modeling
SARM enhances reward model interpretability by projecting hidden states into sparse features using a Sparse Autoencoder, allowing rewards to be calculated as a linear combination of understandable concepts.
Core Problem
Traditional scalar reward models in RLHF are opaque black boxes that offer no explanation for their scores and cannot be easily adjusted when user preferences shift.
Why it matters:
- Opacity prevents verifying if models align with human values or merely exploit spurious correlations in training data
- Static reward models cannot adapt to changing user needs without expensive retraining or fine-tuning
- Existing multidimensional reward models increase annotation costs significantly and still lack granular feature-level transparency
Concrete Example:
A scalar reward model might assign a low score to a helpful response without explanation. It is unclear if the penalty is due to factual inaccuracy, safety violations, or tone. SARM decomposes this score into features like 'ethical reasoning' (positive) or 'hallucination' (negative), enabling precise diagnosis.
Key Novelty
Sparse Autoencoder-enhanced Reward Model (SARM)
- Integrates a pretrained Sparse Autoencoder (SAE) into the intermediate layers of a reward model to translate dense neural activations into sparse, human-understandable features
- Computes the final scalar reward as a weighted sum of these interpretable features, making the reward assignment explicitly decomposable
- Enables 'steering' of the reward model by manually adjusting the weights of specific features (e.g., upweighting 'safety') without retraining
Architecture
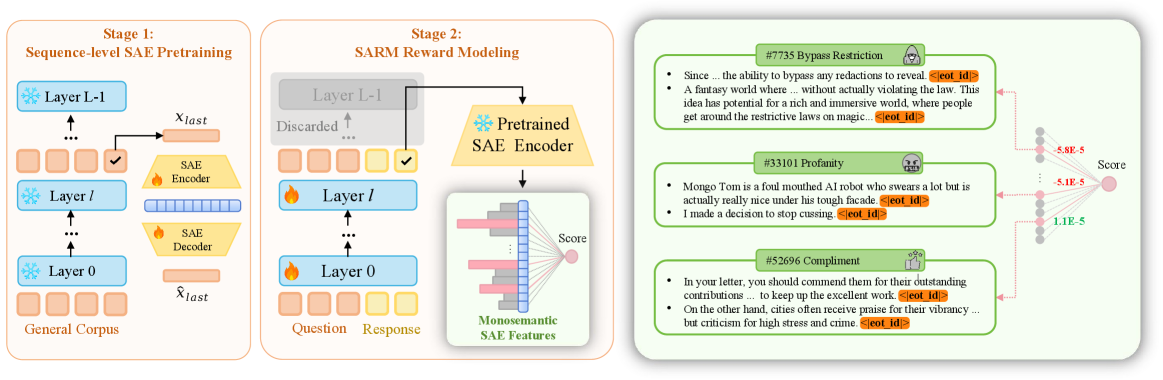
The training pipeline of SARM, showing the transition from standard LLM layers to the Sparse Autoencoder and finally to the linear reward head.
Evaluation Highlights
- SARM achieves superior performance relative to conventional reward models on RewardBench 2, particularly in safety and alignment metrics
- Case studies demonstrate successful manipulation of reward distributions for specific features (e.g., safety) by adjusting feature weights, with minimal impact on unrelated distributions
- Identifies clear monosemantic features (e.g., 'ethical considerations', 'mathematical reasoning') that correlate with human preferences
Breakthrough Assessment
8/10
Significant step for RLHF transparency. Successfully bridges mechanistic interpretability (SAEs) with practical reward modeling, offering both explanation and control without needing expensive multidimensional labels.