📝 Paper Summary
Test-time alignment
Reward modeling
Controlled decoding
GenARM utilizes a novel Autoregressive Reward Model that predicts dense next-token rewards to efficiently guide frozen LLMs toward human preferences without expensive full-sequence rollouts.
Core Problem
Existing test-time alignment methods rely on trajectory-level reward models that only score complete responses, making next-token selection either inaccurate (if applied to partial text) or computationally prohibitive (if requiring full rollouts).
Why it matters:
- Training-time alignment (like RLHF/DPO) is expensive and rigid, requiring retraining for new preferences.
- Prior test-time methods like Transfer-Q are too slow for real-time applications because they must simulate complete futures for every token decision.
- Naive application of standard reward models to partial sentences (ARGS) leads to poor guidance and gibberish generation.
Concrete Example:
When generating 'He decided to...', a standard reward model cannot score the next token 'smile' without seeing the full sentence 'He decided to smile at the neighbor.' To pick the best token, prior methods must generate full completions for 'smile', 'steal', 'wait', etc., which is extremely slow.
Key Novelty
Autoregressive Reward Model (Autoregressive RM)
- Parametrizes the reward function as a log-probability distribution, decomposing the total reward into a sum of token-level conditional log-probabilities.
- This allows the reward model to act like a language model, providing immediate 'dense' rewards for every next-token candidate without needing to see the future.
Architecture
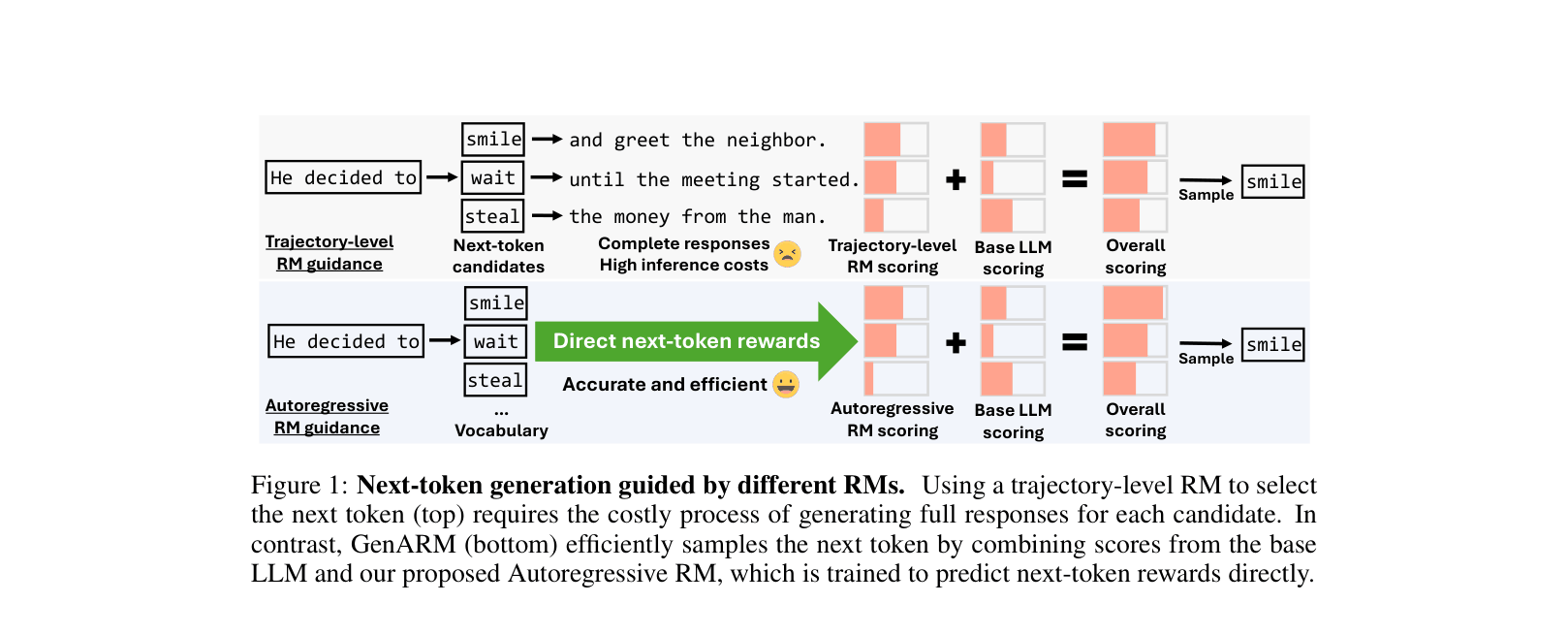
Comparison of next-token selection between Trajectory-level RM (top) and GenARM/Autoregressive RM (bottom).
Evaluation Highlights
- Outperforms test-time baseline ARGS by a wide margin (65.33% win rate) on HH-RLHF while maintaining comparable inference speed (7.28s vs 7.74s).
- Matches the performance of training-time alignment (DPO) with a 48.00% win rate against it, without requiring any gradient updates to the base LLM.
- Enables weak-to-strong generalization: a 7B Autoregressive RM successfully guides a frozen 70B LLM, recovering >70% of the performance gap between the base model and a fully trained DPO model.
Breakthrough Assessment
8/10
Offers a theoretically grounded and highly efficient solution to test-time alignment, effectively bridging the gap between expensive training-based methods and slow or inaccurate inference-based methods.

