📝 Paper Summary
Process Reward Models (PRM)
Mathematical Reasoning
Active Learning
ActPRM reduces process reward model annotation costs by 50-80% by using an ensemble of heads to detect and actively select only uncertain reasoning steps for labeling by expensive judges.
Core Problem
Training Process Reward Models (PRMs) requires fine-grained step-level annotations that are prohibitively expensive to obtain from humans or high-capability LLMs at scale.
Why it matters:
- State-of-the-art PRMs like Qwen2.5-Math-PRM require massive annotation budgets (billions of tokens) to filter Monte Carlo rollouts or label trajectories
- Existing methods either rely on expensive human experts or computationally heavy outcome-based sampling (MathShepherd) that struggles to pinpoint the exact first error step
- Scaling supervision for mathematical reasoning is bottlenecked by the cost of high-quality labels, limiting the ability to improve Chain-of-Thought (CoT) reliability
Concrete Example:
In a dataset of 1 million math solutions, a standard approach might label all trajectories, wasting resources on easy/obvious steps. ActPRM identifies that the model is confident about the first 3 steps but uncertain about the 4th, selecting only that specific trajectory for expensive annotation by a stronger model like QwQ-32B.
Key Novelty
Uncertainty-Aware Active Learning for Process Supervision (ActPRM)
- Trains a PRM with an ensemble of lightweight classification heads on a shared backbone to estimate both aleatoric (inherent) and epistemic (model) uncertainty per reasoning step
- Filters the training data pool by discarding trajectories where the ensemble is confident, retaining only 'uncertain' samples where heads disagree or confidence is low
- Labels only the selected uncertain subset using a high-cost reasoning model (Judge), drastically reducing the total token budget required for supervision
Architecture
The Active Learning workflow for PRM training.
Evaluation Highlights
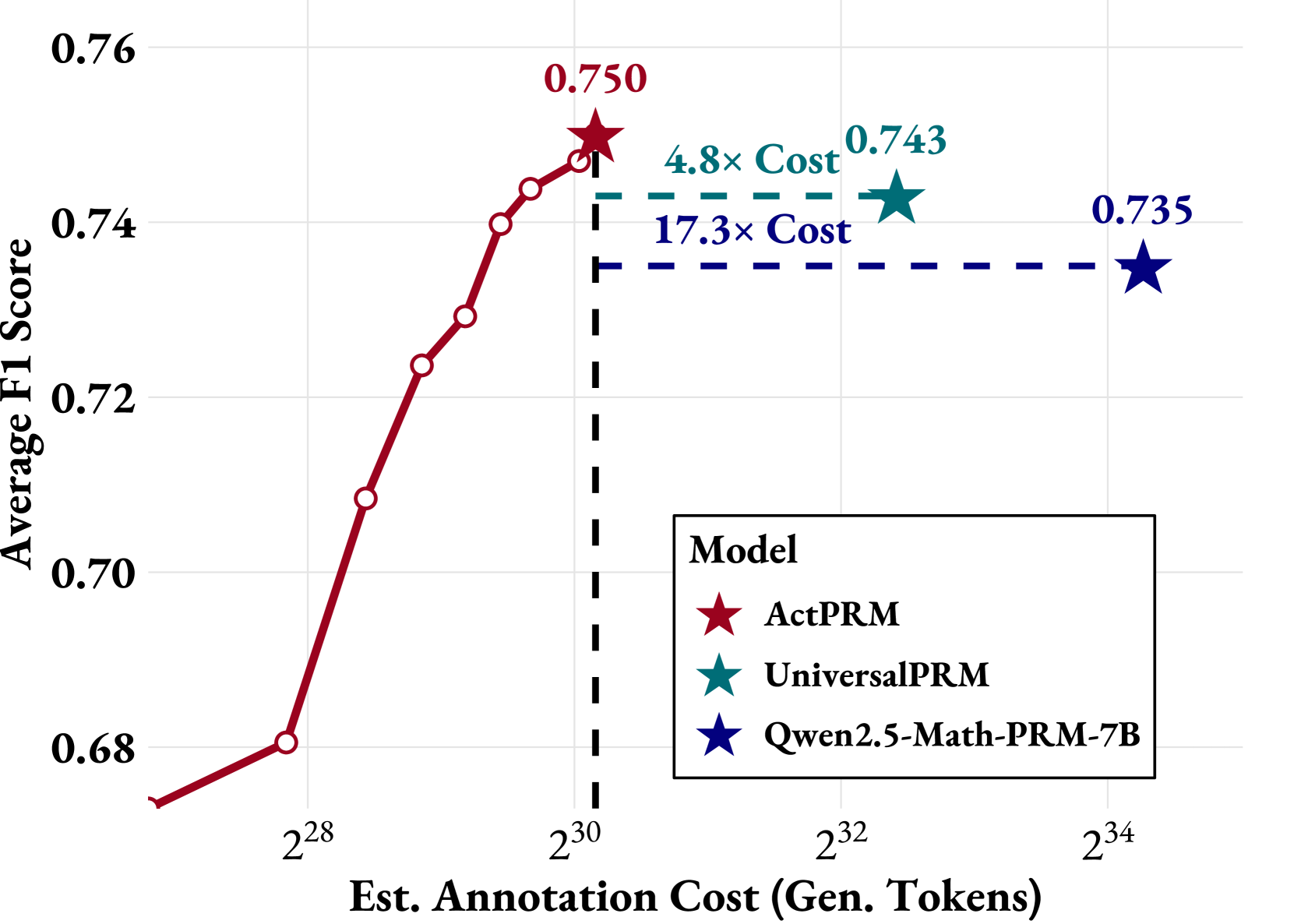
- Achieves 75.0% F1 on ProcessBench, setting a new SOTA while using only ~6% of the annotation budget of Qwen2.5-Math-PRM-7B (73.5%)
- Outperforms UniversalPRM (74.3%) by 0.7% on ProcessBench while consuming only 20% of its generated token budget
- Matches the performance of full-data training (100k samples) using only 50% of the data in a pool-based active learning setting
Breakthrough Assessment
8/10
Significantly improves the data efficiency of PRM training (up to 5x cheaper than SOTA) while improving performance. The active learning application to process supervision is a practical and impactful advancement.