📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reward Modeling
RRM mitigates reward hacking by augmenting training data with counterfactual response pairs to causally disentangle genuine contextual quality signals from spurious artifacts like length or formatting.
Core Problem
Traditional Reward Models (RMs) fail to distinguish between prompt-dependent quality signals and prompt-independent artifacts (e.g., length), leading to 'reward hacking' where models exploit these artifacts.
Why it matters:
- LLMs aligned via RLHF often become unnecessarily verbose or overuse formatting because RMs learn to prioritize these easy-to-spot artifacts over actual quality
- Current training pairs are always on-topic, preventing the model from seeing 'counterfactuals' where artifacts exist without the correct context
- Reward hacking degrades the actual helpfulness and honesty of aligned models despite high reward scores
Concrete Example:
If 80% of preferred responses in a dataset are long, a standard RM learns to simply count tokens to predict the winner. Consequently, the aligned Policy generates bloated, repetitive paragraphs even for simple yes/no questions to maximize this length-biased reward.
Key Novelty
Causal Data Augmentation for Reward Modeling
- Models the preference problem as a causal graph distinguishing 'Contextual Signals' (depend on prompt) from 'Artifacts' (independent of prompt)
- Constructs augmented training pairs by mixing responses from different prompts to break the correlation between artifacts and preference labels
- Trains the reward model to prefer contextual responses over non-contextual ones regardless of artifacts, forcing it to learn actual prompt-response relevance
Architecture
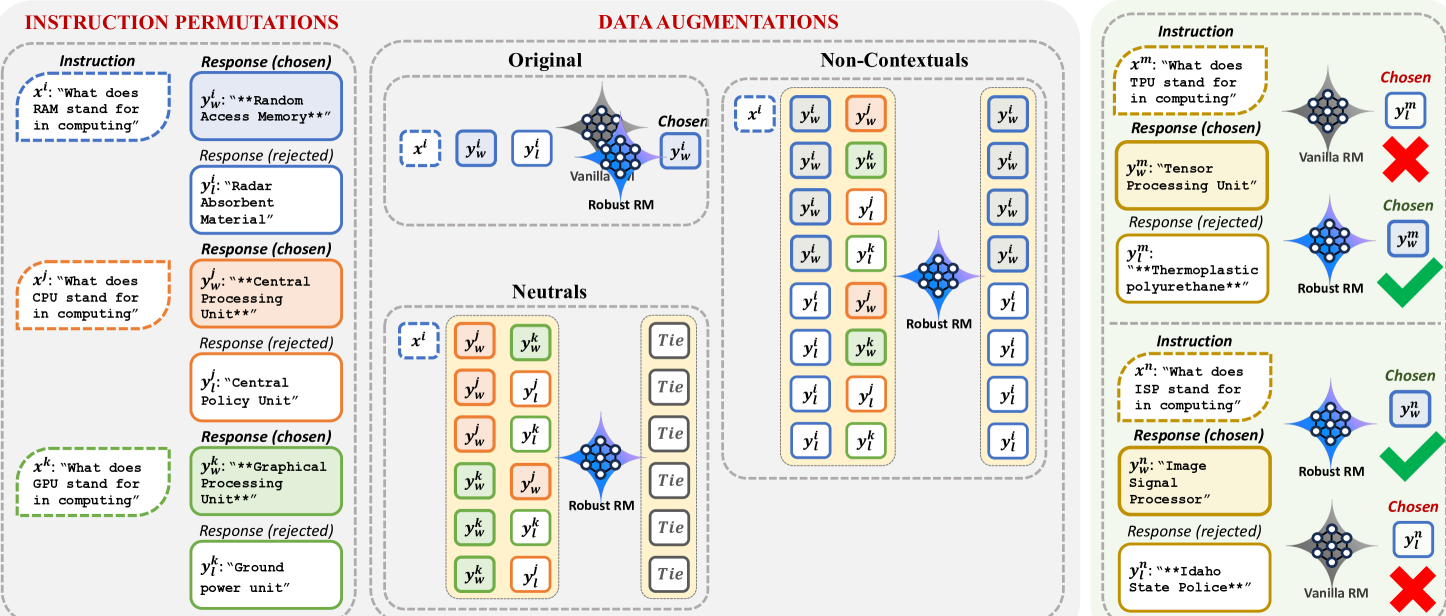
The RRM pipeline showing how training data is augmented. It illustrates mixing responses from different examples to create pairs where artifacts are balanced or randomized.
Evaluation Highlights
- +3.54% accuracy improvement on RewardBench (80.61% to 84.15%) using Gemma-2-9b-it
- +19.03% increase in length-controlled win-rate on AlpacaEval-2 (33.46% to 52.49%) for a DPO policy trained with RRM
- +1.04 score improvement on MT-Bench (7.27 to 8.31) for the downstream aligned policy
Breakthrough Assessment
7/10
Significant improvements in both reward modeling accuracy and downstream policy performance by addressing a fundamental causal flaw in RLHF data construction. The method is simple yet highly effective.