📝 Paper Summary
LLM Pre-training
Small Language Models (SLMs)
Training Stability
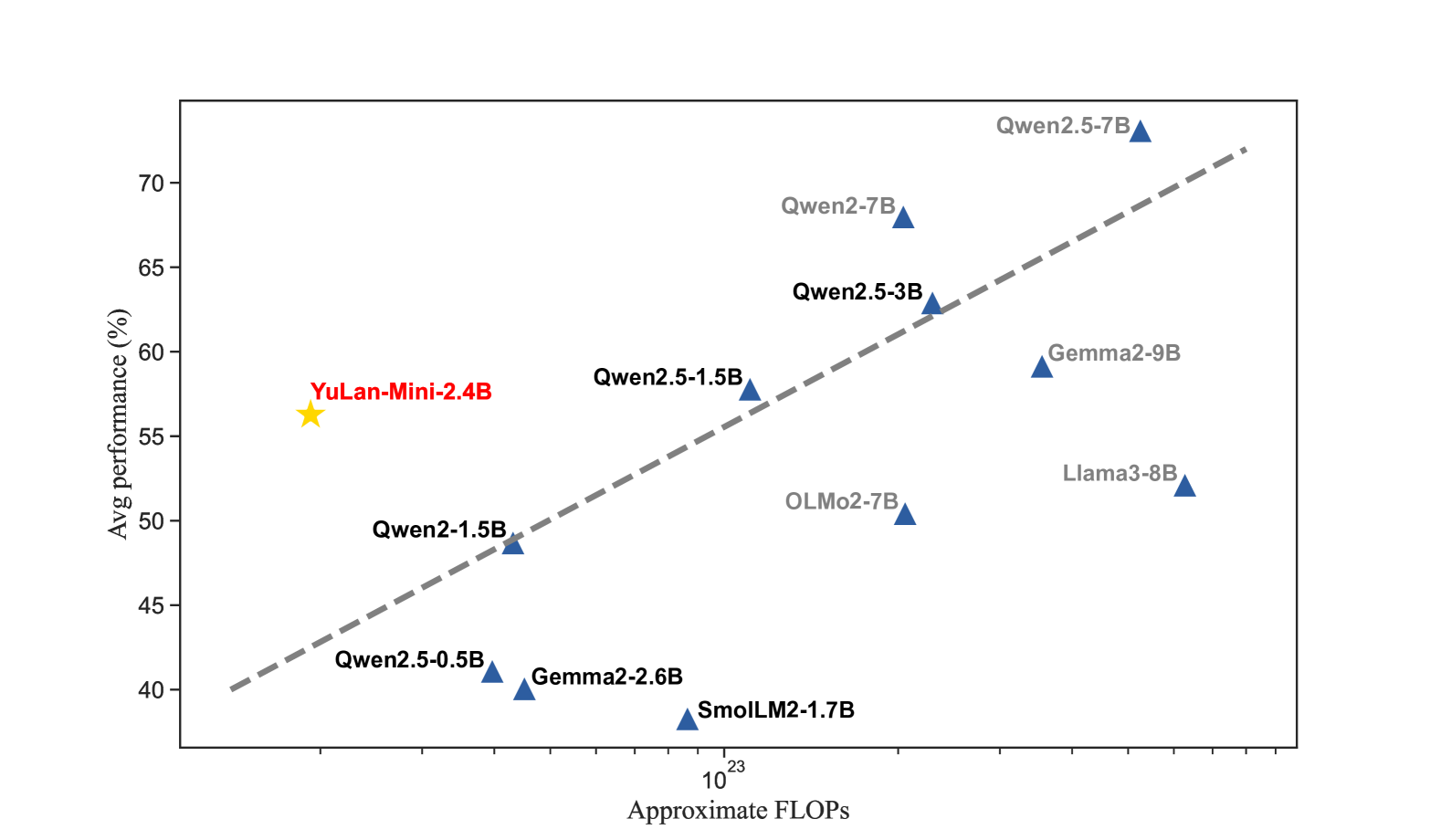
YuLan-Mini is a 2.42B parameter model that achieves top-tier performance by combining a rigorous data pipeline, stability-focused optimization techniques like hidden state monitoring, and a targeted annealing phase.
Core Problem
Developing competitive Large Language Models (LLMs) with limited compute resources (e.g., in university labs) is difficult due to training instability and the need for massive, high-quality data.
Why it matters:
- Open-source models often underperform industry counterparts due to data and compute constraints
- Training instability (loss spikes, gradient explosions) frequently causes failures in large-scale runs, wasting expensive resources
- University labs lack the massive infrastructure of industry giants, necessitating higher data efficiency and stability
Concrete Example:
In standard pre-training, hidden state variances can grow exponentially across layers. Without intervention, this leads to gradient explosion and loss spikes, causing the training run to diverge or fail, as observed in the paper's proxy model experiments.
Key Novelty
Stability-First Pre-training for Resource-Constrained Environments
- Combines data cleaning with a curriculum schedule that adjusts data mix based on model performance and perplexity during training
- Mitigates training instability by monitoring hidden state variance and applying specific initialization and re-parameterization techniques
- Utilizes a two-phase context extension strategy (annealing) to efficiently transition from 4K to 28K context length using high-quality synthetic and instruction data
Architecture
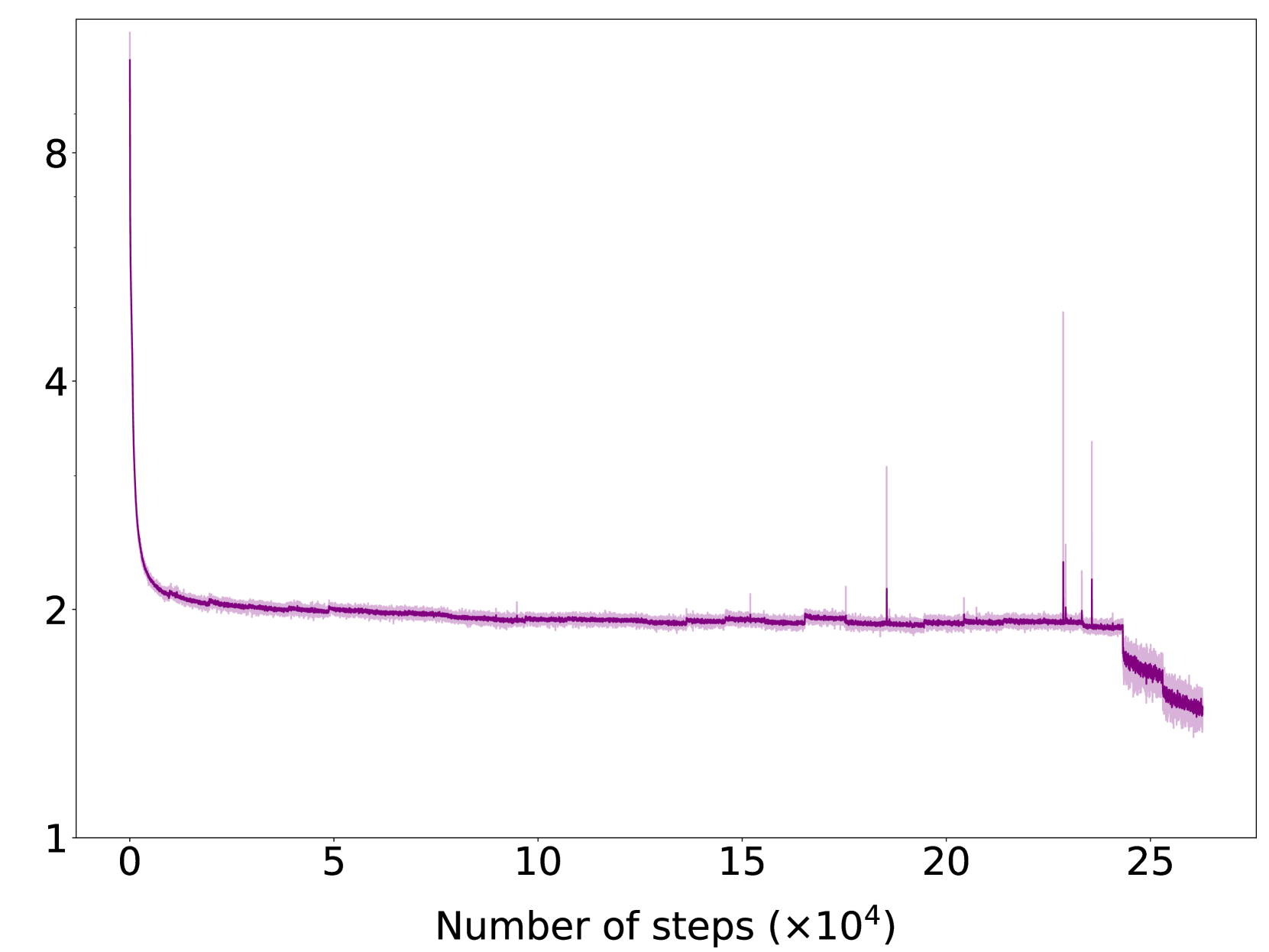
Charts analyzing training stability indicators (Hidden State Variance, Gradient Norm) across layers and steps
Evaluation Highlights
- YuLan-Mini (2.42B parameters) achieves 64.00 on HumanEval (zero-shot), outperforming Llama-3-8B-Instruct (62.2)
- On MATH-500 (four-shot), the model scores 37.80, surpassing Qwen2.5-3B (36.0)
- Achieves 49.10 on MMLU (five-shot), competitive with larger models like Gemma-2-2B (52.4) and Qwen2.5-3B (51.8)
Breakthrough Assessment
7/10
While not a new architecture, it provides a highly valuable recipe for training high-performance small models with limited resources, achieving results competitive with industry models significantly larger or trained on more data.