📝 Paper Summary
Multimodal Reasoning
Process Reward Models (PRM)
DreamPRM improves multimodal reasoning by training a Process Reward Model using bi-level optimization to automatically learn domain weights that prioritize high-quality datasets and filter out noise.
Core Problem
Training effective Process Reward Models (PRMs) for multimodal tasks is hampered by severe quality imbalances across datasets, where noisy or trivial samples degrade the model's ability to generalize.
Why it matters:
- Multimodal inputs create a massive distribution shift from training to testing, making generalization far harder than in text-only settings.
- Existing datasets contain many 'easy' or noisy samples (e.g., unnecessary modalities) that contribute little to learning but consume training budget.
- Naive combinations of datasets fail because high-quality signals get drowned out by low-quality ones, leading to unreliable reward models.
Concrete Example:
In Figure 1, some datasets contain questions with negligible difficulty or unnecessary images that provide no reasoning challenge. A standard PRM treats these equal to complex geometry problems, learning trivial correlations instead of robust verification logic.
Key Novelty
Bi-Level Optimization for Domain Reweighting
- Treats dataset importance weights as learnable parameters in an upper-level optimization loop, while the PRM parameters are updated in a lower-level loop.
- Uses a novel 'aggregation function loss' on a high-quality meta-dataset (validation set) to guide the learning of domain weights, ensuring the PRM prioritizes data that improves final answer selection.
- Dynamically down-weights noisy or easy domains during training without requiring manual filtering rules.
Architecture
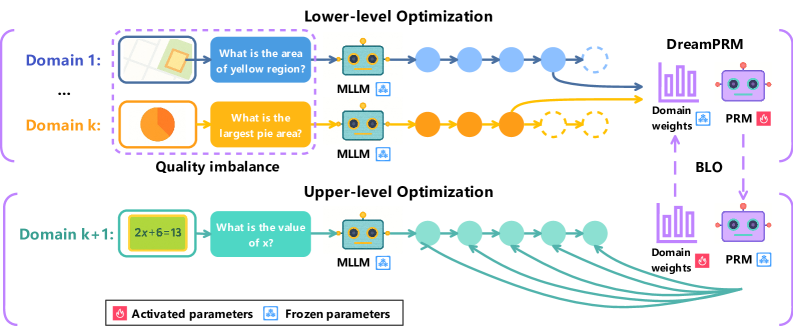
Overview of the DreamPRM training framework showing the bi-level optimization process.
Evaluation Highlights
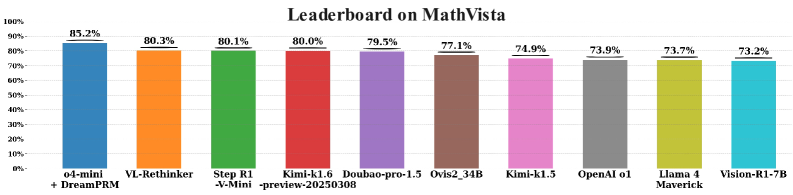
- Achieves 85.2% top-1 accuracy on the MathVista leaderboard using o4-mini, surpassing state-of-the-art models like GPT-4V and Gemini-1.5-Pro.
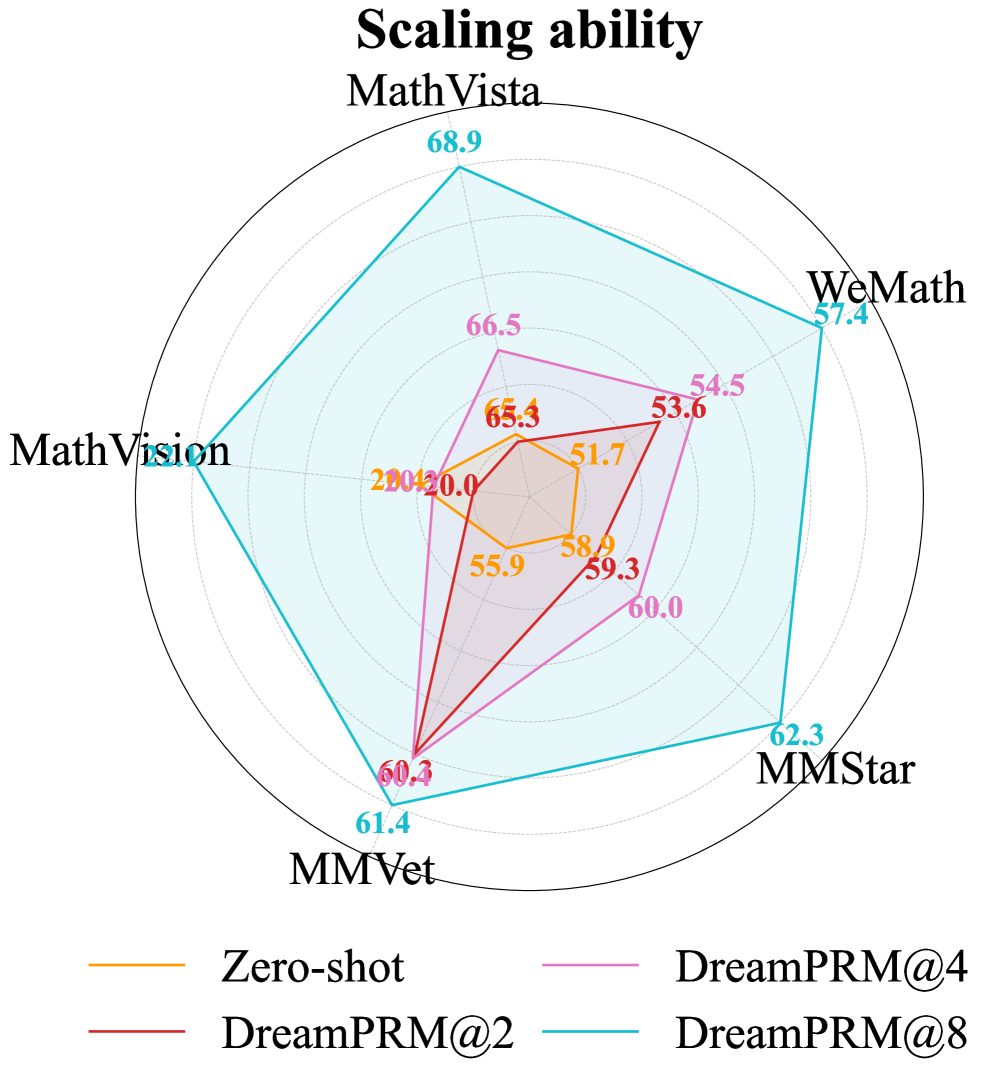
- Consistently improves base model (InternVL-2.5-8B-MPO) performance by ~4% on average across five multimodal reasoning benchmarks compared to vanilla PRM.
- Outperforms heuristic data selection strategies (s1-PRM, CaR-PRM) by 1-2%, proving that learned weights are superior to manual rules.
Breakthrough Assessment
8/10
Strong empirical results on major leaderboards (MathVista) and a theoretically sound application of bi-level optimization to the specific problem of data quality in multimodal PRMs.