📝 Paper Summary
Text-to-Image Generation
Preference Optimization
LPO repurposes the pre-trained diffusion model itself as a noise-aware reward model to perform fast, step-level preference optimization directly in the latent space without expensive image decoding.
Core Problem
Existing methods use Vision-Language Models (VLMs) as reward models, which require converting noisy internal states into clean pixels at every step—a slow process that produces unreliable, blurry images at high noise levels.
Why it matters:
- Pixel-level Reward Models (PRMs) must decode latent representations to pixels, slowing down training by 2.5-28x compared to the proposed method
- VLMs trained on clean images fail to accurately judge the highly noisy, blurry images generated during the early steps of diffusion, leading to poor optimization at those stages
- Current reward models lack sensitivity to timesteps, making it difficult to assess generation progress contextually
Concrete Example:
At timestep t=900 (highly noisy), a standard reward model sees a meaningless blur after decoding, yet must predict if the final image will be good. It fails because the blur is out-of-distribution for the VLM. In contrast, LPO uses the diffusion model's own internal features, which are naturally trained to understand these noisy states.
Key Novelty
Latent Preference Optimization (LPO) with Latent Reward Model (LRM)
- Repurposes the diffusion model (U-Net/DiT) as a reward model (LRM) by extracting visual features from noisy states and comparing them with text prompts, avoiding VAE decoding
- Introduces Multi-Preference Consistent Filtering (MPCF) to clean training data, ensuring 'winning' images are superior in both aesthetics and text alignment so preference holds even under noise
- Visual Feature Enhancement (VFE) injects text-alignment information into the reward model by contrasting conditional and unconditional feature representations
Architecture
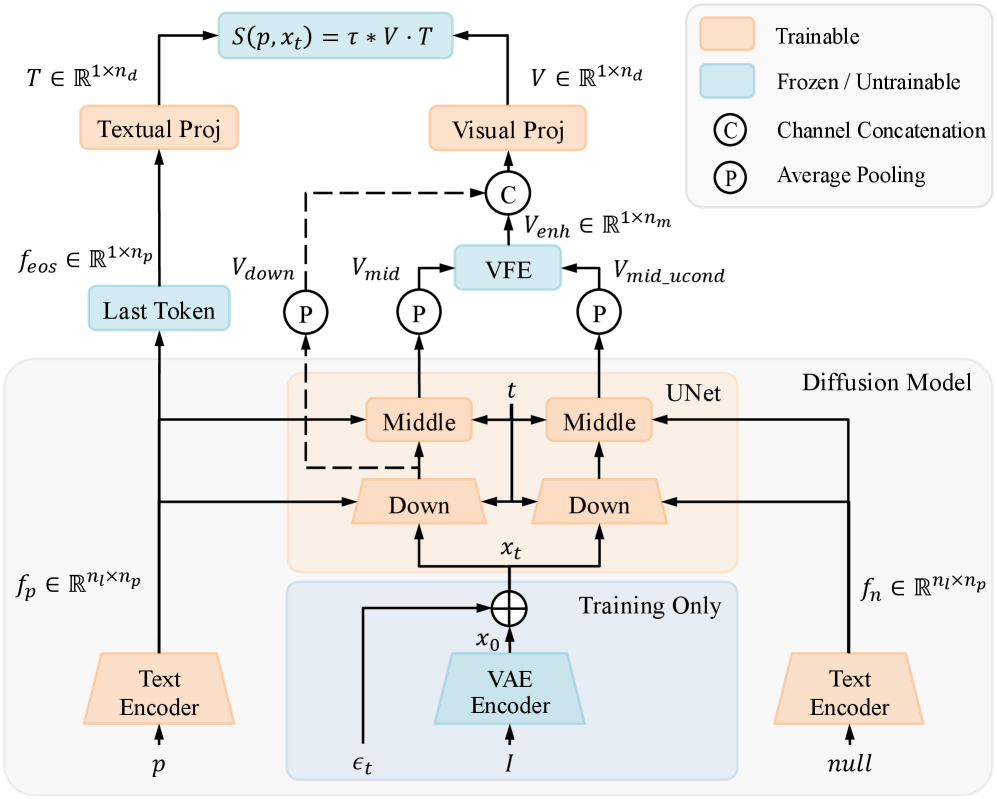
Overview of Latent Reward Model (LRM) architecture and Latent Preference Optimization (LPO) pipeline.
Evaluation Highlights
- Achieves 10-28x training speedup over Diffusion-DPO and 2.5-3.5x over SPO (Step-by-step Preference Optimization) by eliminating VAE decoding
- Outperforms SDXL Base with a 67.48% win-rate on Pick-a-Pic v1 test set, surpassing SPO (64.21%) and Diffusion-DPO (65.25%)
- Reduces GPU memory usage significantly: LPO requires ~32GB vs Diffusion-DPO's ~68GB for SDXL training
Breakthrough Assessment
8/10
Significantly addresses the computational bottleneck of reinforcement learning for diffusion models by moving the reward signal to latent space. The speedups are substantial (order of magnitude) while maintaining or improving quality.
