📝 Paper Summary
Instruction-guided image editing
Reward modeling / Preference learning
EditReward is a multi-dimensional, uncertainty-aware reward model trained on 200K expert-annotated image editing pairs, enabling the selection of high-quality training data to improve open-source editing models.
Core Problem
Existing reward models for image editing (LPIPS, CLIP, general VLMs) align poorly with human preferences, failing to reliably distinguish high-quality edits for data filtering.
Why it matters:
- Current open-source editing models lag behind closed-source ones (like GPT-Image-1) due to a lack of high-quality training data
- Scaling up training data requires automatic filtering, but current rewards are too noisy or biased to serve as reliable filters
- Crowd-sourced preference datasets often suffer from low inter-annotator agreement and inconsistency
Concrete Example:
A tie in overall quality often masks trade-offs: one edit might follow instructions perfectly but have artifacts, while another is pretty but ignores the prompt. Standard models treat this as a generic tie, losing the nuanced signal that humans provided.
Key Novelty
Multi-Dimensional Uncertainty-Aware Reward Modeling
- Decomposes edit quality into 'Instruction Following' and 'Visual Quality', predicting Gaussian distributions for each to capture annotator uncertainty
- Uses a novel tie-disentanglement strategy: splits 'tied' pairs into two conflicting training samples (A>B on dimension X, B>A on dimension Y) to learn granular trade-offs
- Trains on a new dataset (EditReward-Data) of 200K expert-annotated pairs rather than noisy crowd-sourced labels
Architecture
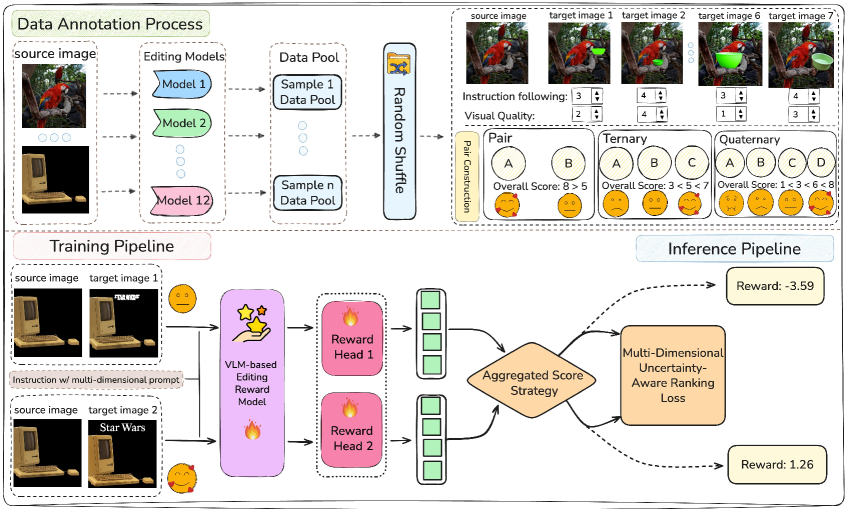
Conceptual flow of the reward calculation: VLM backbone extracts features, which are fed into MLP heads predicting Gaussian distributions for two dimensions (IF and VQ).
Evaluation Highlights
- Achieves 65.72% accuracy on GenAI-Bench, significantly outperforming GPT-5 (59.61%) and GPT-4o
- Scores 63.62% on AURORA-Bench, surpassing OpenAI-GPT-4o (50.81%) by a large margin
- Fine-tuning Step1X-Edit on just the top 20K samples filtered by EditReward improves Overall Score from 6.78 to 7.086, matching state-of-the-art Doubao-Edit
Breakthrough Assessment
9/10
Establishes a new SOTA for editing reward models, beating GPT-5. The release of 200K expert annotations and the methodology for disentangling ties/uncertainty are significant contributions to the field.