📝 Paper Summary
Video Spatio-Temporal Reasoning
Reinforcement Learning for MLLMs
Video-STR enhances MLLM video understanding by training models to explicitly generate and verify object relation graphs that capture physical spatio-temporal topology.
Core Problem
MLLMs struggle with precise spatio-temporal reasoning (e.g., object layouts, motion trajectories) because they focus on pixel-level changes rather than underlying physical information.
Why it matters:
- Current methods relying on 2D cognitive maps or pixel localization fail to capture rotation-invariant physical topology necessary for robust reasoning
- Lack of precise spatial understanding restricts MLLM application in high-precision fields like embodied intelligence and VR
- Existing video datasets lack sufficient supervision for complex spatio-temporal dynamics
Concrete Example:
When asked about the relative direction of two objects moving in a video, standard MLLMs often misinterpret the layout due to camera rotation. Video-STR constructs a graph where edges represent relative distances and angles, allowing the model to verify its reasoning against the physical ground truth.
Key Novelty
Graph-based Reinforcement Learning with Verifiable Reward (RLVR)
- Introduces a reasoning mechanism where the model generates an inter-object relation graph (nodes=objects, edges=spatial relations) during its chain-of-thought
- Extends GRPO (Group Relative Policy Optimization) with specific graph-based rewards that verify the topological accuracy of the generated graph against ground truth attributes (distance, angle)
Architecture

The graph-based reasoning mechanism and reward formulation. It illustrates how the model generates a topology graph during thinking and how rewards are calculated based on ground truth.
Evaluation Highlights
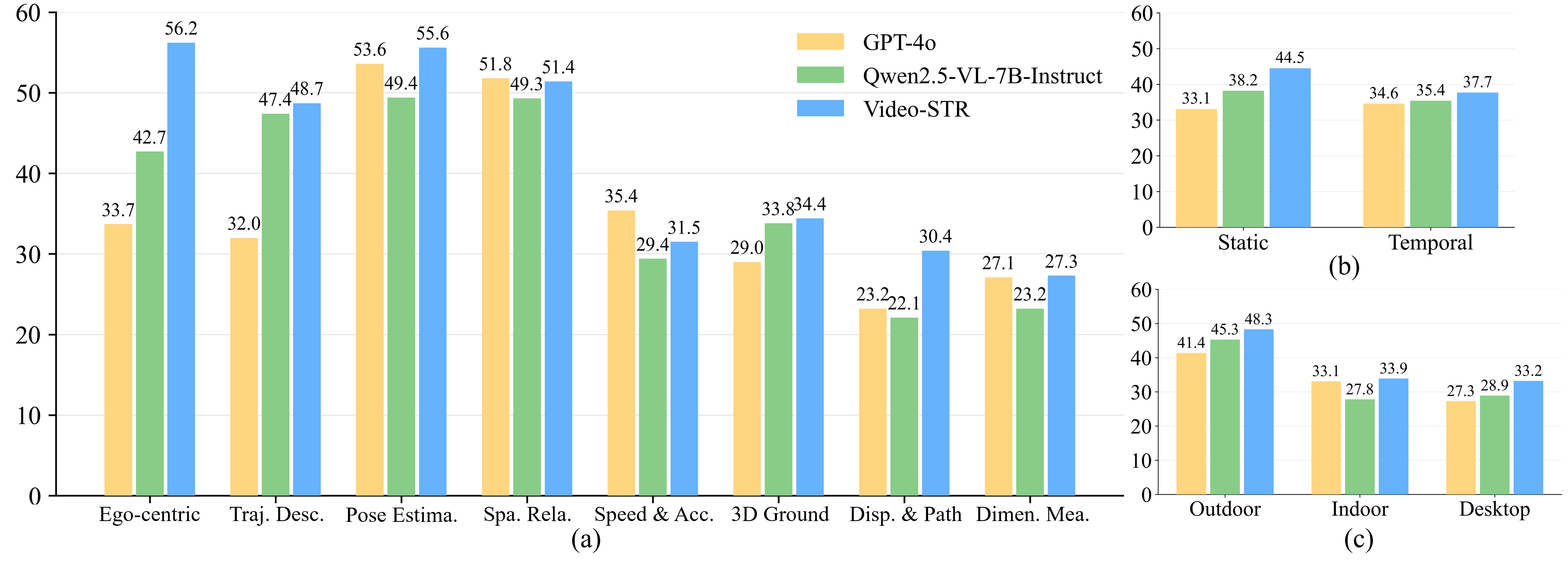
- Outperforms the base model (Qwen2.5-VL-7B-Instruct) by 13% on STI-Bench, a benchmark for spatio-temporal intelligence
- Surpasses GPT-4o on spatio-temporal reasoning benchmarks, demonstrating superior capability in modeling dynamic object interactions
- Achieves state-of-the-art results across spatial (VSI-Bench), temporal (Video-MME), and spatio-temporal (V-STaR) benchmarks
Breakthrough Assessment
8/10
Addresses a critical weakness in MLLMs (physical spatial reasoning) with a novel neuro-symbolic approach (graph verification in RL) and a large-scale specialized dataset.