📊 Experiments & Results
Evaluation Setup
Evaluation on standard remote sensing benchmarks using generated reasoning chains
Benchmarks:
- RSVQA-LR (Visual Question Answering (Low Resolution))
- RSVQA-HR (Visual Question Answering (High Resolution))
- METER-ML (Scene Classification)
- DIOR-RS (Visual Grounding / Object Detection)
- LHRS-Bench (General Remote Sensing Knowledge/Reasoning)
Metrics:
- Accuracy (for VQA and Classification)
- IoU / Average Precision (for Visual Grounding)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| 1-shot RLVR demonstrates immediate significant gains over the base model, proving latent reasoning capabilities can be unlocked with minimal signal. | ||||
| RSVQA-LR | Accuracy | 65.65 | 77.30 | +11.65 |
| DIOR-RS (Visual Grounding) | Accuracy/IoU | 0.00 | 24.38 | +24.38 |
| Scaling to 128 examples allows the method to match or exceed baselines trained on significantly larger datasets (2,000 to millions). | ||||
| RSVQA-LR | Accuracy | 81.25 | 80.96 | -0.29 |
| UCM (Classification) | Accuracy | 87.14 | 88.10 | +0.96 |
| RSVQA-LR | Accuracy | 80.68 | 80.96 | +0.28 |
Experiment Figures
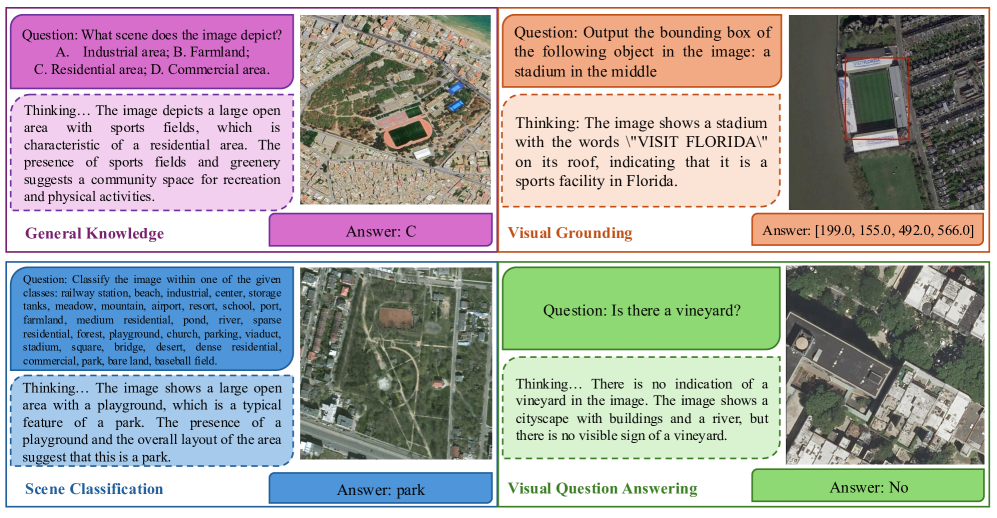
Qualitative examples of the model's reasoning traces on classification and VQA tasks
Main Takeaways
- Base VLMs possess latent reasoning abilities for remote sensing that can be unlocked with just 1 example and verifiable rewards, without caption supervision.
- Training with ~128 curated examples via RLVR is a cost-effective 'sweet spot', matching performance of models trained on thousands of examples.
- 1-shot training exhibits 'task-specific overfitting' (performance drops on the specific dataset split used for the single example) but maintains or improves generalization on other tasks.
- Visual Grounding benefits massively from RLVR (0% to ~30%) but remains the hardest task to match full-supervision performance on due to the precision required.