📝 Paper Summary
Medical Reasoning
Clinical Large Language Models
Fleming-R1 improves medical reasoning by combining knowledge-graph-guided data synthesis, chain-of-thought distillation, and reinforcement learning that rewards verifiable formatting and accuracy rather than just final answers.
Core Problem
Current medical AI models often provide correct answers without transparent or reliable reasoning, leading to 'answer without justification' and safety risks in clinical settings.
Why it matters:
- A confident but incorrect answer in medicine is unsafe; clinicians need to audit the reasoning steps, not just the final output
- Existing models struggle with long-tail diseases and multi-step inference because training data is dominated by static QA pairs with sparse rationale supervision
- Naive optimization for accuracy fails to correct specific reasoning failure modes like dosing errors or unjustified diagnostic leaps
Concrete Example:
State-of-the-art LLMs may achieve 73% accuracy on abdominal conditions like appendicitis (vs 89% for humans) but fail to explain why, often hallucinating evidence or skipping logical steps required for verification.
Key Novelty
Fleming-R1: RLVR for Medical Reasoning
- Reasoning-Oriented Data Strategy (RODS): Generates synthetic reasoning-intensive questions from a medical knowledge graph to cover rare diseases and multi-hop relationships
- CoT Cold-Start: Distills high-quality reasoning traces from a strong teacher model using iterative refinement (backtracking and self-correction) to initialize the student
- Two-stage RLVR (Reinforcement Learning from Verifiable Rewards): Uses Group Relative Policy Optimization (GRPO) to first consolidate basic formatting/skills, then mine hard samples to fix persistent failure modes
Architecture
The overall training pipeline of Fleming-R1, illustrating the flow from data preparation to RL enhancement.
Evaluation Highlights
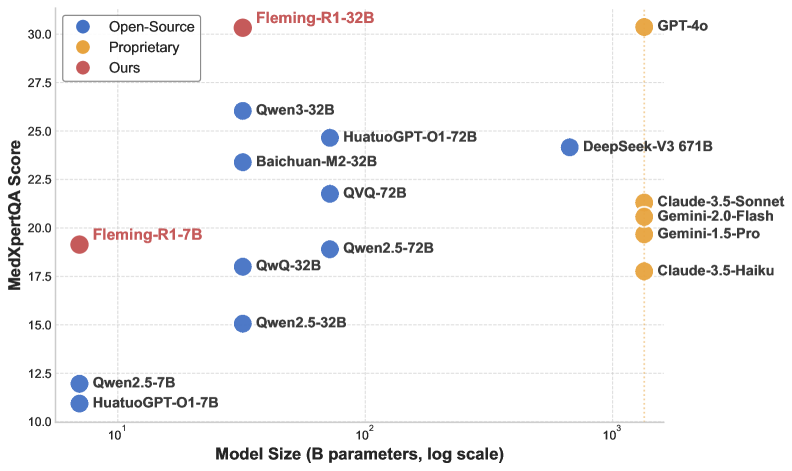
- Fleming-R1-7B surpasses much larger 72B-class baselines on key medical benchmarks
- Fleming-R1-32B achieves near-parity with GPT-4o on multiple medical reasoning benchmarks
- Consistently outperforms strong open-source alternatives through parameter-efficient training tailored for reasoning depth
Breakthrough Assessment
8/10
Strong methodological integration of synthetic data, distillation, and RLVR (Reinforcement Learning from Verifiable Rewards) specifically for medicine. Demonstrates high parameter efficiency (7B beating 72B) and emphasizes verifiability.