📝 Paper Summary
Reinforcement Learning with Verifiable Reward (RLVR)
Curriculum Learning for LLMs
Chain-of-Thought (CoT) Optimization
EvoCoT overcomes exploration bottlenecks in reinforcement learning by first generating answer-guided reasoning paths for unsolved problems, then training the model on progressively shorter versions of these paths to gradually increase difficulty.
Core Problem
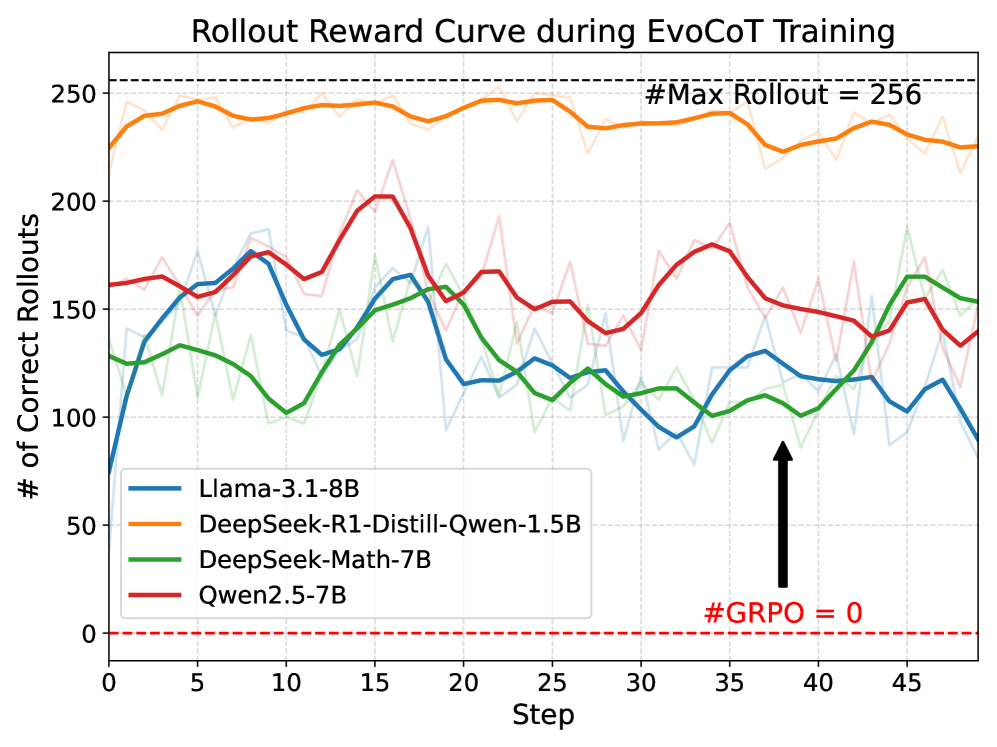
In Reinforcement Learning with Verifiable Rewards (RLVR), LLMs often face exploration bottlenecks on hard problems where rollout accuracy is near zero, resulting in sparse rewards and failed learning.
Why it matters:
- Current RLVR methods (like GRPO) discard hard problems where the model fails to find a solution, wasting valuable training data
- Reliance on teacher models for distillation limits scalability and is costly for flagship models
- Existing curriculum methods often filter out hard problems rather than enabling the model to solve them, restricting reasoning improvement
Concrete Example:
On the GSM8K training set, Qwen2.5-7B fails to solve 8.8% of problems even after standard RL training because the solution space is too vast to explore randomly. EvoCoT enables the model to solve these by starting with full reasoning traces and gradually removing steps.
Key Novelty
Self-Evolving Curriculum via Reverse CoT Reduction
- Generates reasoning paths for unsolved problems by conditioning the LLM on the ground-truth answer, then filtering for consistency (Answer-Guided Generation)
- Creates a natural curriculum by progressively truncating these self-generated paths from the end, forcing the model to complete increasingly larger portions of the reasoning independently
Architecture
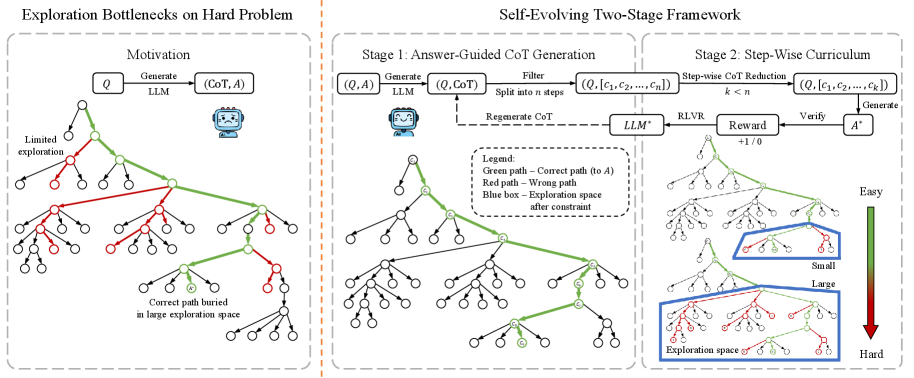
Conceptual diagram of EvoCoT's two-stage process: Self-Generation and Curriculum Learning.
Evaluation Highlights
- +21.7% accuracy improvement on previously unsolved training problems for R1-Qwen-1.5B compared to GRPO
- Achieves 53.5% pass@1 on MATH benchmark with Qwen2.5-7B, outperforming SimpleRL (51.2%) and SFT (36.9%)
- R1-Qwen-1.5B reaches 51.6% on the challenging Olympiad Bench, setting a new high among compared methods
Breakthrough Assessment
8/10
Elegantly solves the exploration bottleneck without external supervision or teacher models. The reverse-step curriculum is a simple yet highly effective way to leverage hard failures.