📝 Paper Summary
Graph-based RAG pipeline
Schema Matching
KG-RAG4SM improves schema matching by retrieving and ranking relevant subgraphs from large external knowledge graphs to augment LLM prompts with semantic context.
Core Problem
Traditional and LLM-based schema matching methods fail to resolve semantic ambiguities (e.g., acronyms, hidden duplicates) in complex scenarios due to a lack of domain knowledge and common sense.
Why it matters:
- Integrating large-scale heterogeneous databases (e.g., Electronic Health Records) is critical for modern data management but is hindered by semantic heterogeneity.
- Existing similarity-based methods only identify equivalent relationships, ignoring taxonomic ones, while LLMs suffer from hallucinations without external grounding.
- Detecting duplicate attributes across disparate schemas requires domain expertise often missing from standard training data.
Concrete Example:
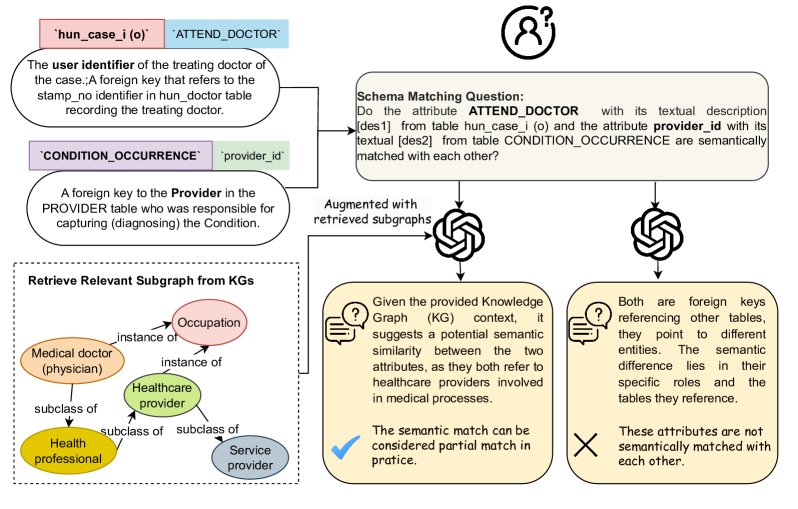
In a healthcare scenario, the attribute 'ATTEND_DOCTOR' in one table is a duplicate of 'DOCTOR' in another, and both map to 'provider_id'. Standard methods fail to match 'ATTEND_DOCTOR' to 'provider_id' because they lack the specific domain knowledge connecting these terms.
Key Novelty
Knowledge Graph-based Retrieval-Augmented Generation for Schema Matching (KG-RAG4SM)
- Augments LLM prompts with subgraphs retrieved from external large-scale Knowledge Graphs (KGs) like Wikidata to provide missing semantic context.
- Introduces a hybrid retrieval strategy combining vector similarity search for entities/relations with BFS (Breadth-First Search) traversal to find relevant connections.
- Employs a ranking scheme to prune irrelevant graph components, preventing context poisoning and keeping the prompt concise.
Architecture
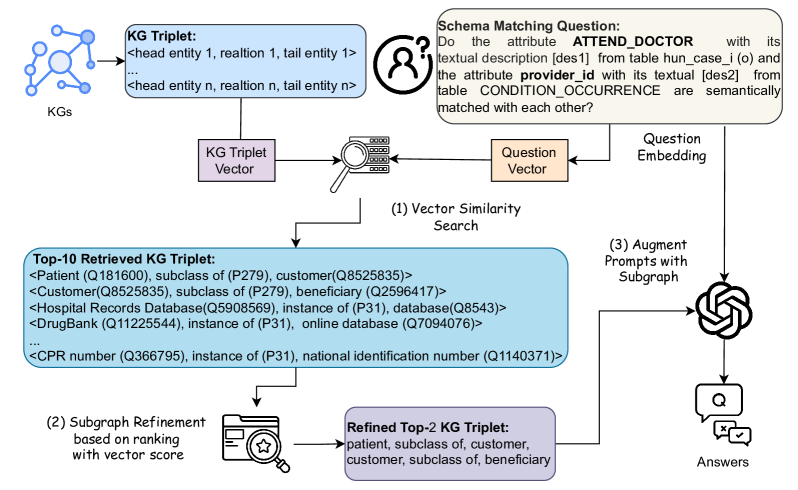
The overall architecture of KG-RAG4SM, illustrating the flow from the input question to final answer generation via KG retrieval.
Evaluation Highlights
- Outperforms LLM-based SOTA (Jellyfish-8B) by +35.89% precision and +30.50% F1 score on the MIMIC dataset.
- With GPT-4o-mini, outperforms PLM-based SOTA (SMAT) by +69.20% precision and +21.97% F1 score on the Synthea dataset.
- Demonstrates scalability and efficiency in end-to-end matching tasks without requiring LLM re-training.
Breakthrough Assessment
7/10
Significant performance gains in domain-specific schema matching by effectively applying Graph RAG. While the RAG concept is known, applying it to schema matching with specific traversal/pruning strategies is a strong contribution.