📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Process Reward Models (PRM)
LLM Mathematical Reasoning
TDRM improves large language model reasoning by training process reward models using temporal difference learning, creating smoother reward signals that enhance both online reinforcement learning and inference-time search.
Core Problem
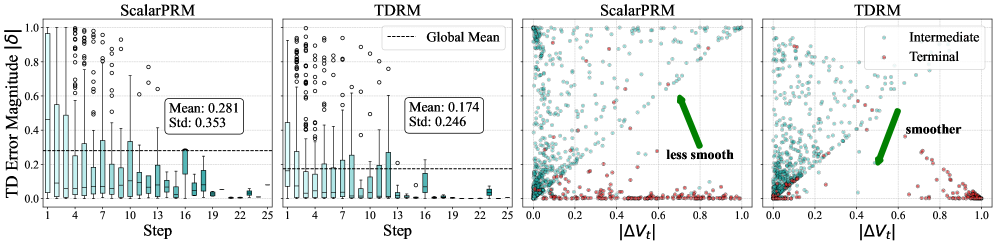
Existing reward models lack temporal consistency, assigning disconnected scores to adjacent reasoning steps, which leads to unstable training signals and inefficient search during inference.
Why it matters:
- Inconsistent rewards make it difficult for models to distinguish which specific step contributed to success or failure, especially in long chain-of-thought reasoning.
- Standard outcome-based rewards provide sparse feedback (only at the end), while current process rewards often fail to update based on future context, leading to misleading guidance.
- Ineffective reward modeling hampers the data efficiency of reinforcement learning, requiring massive datasets to achieve performance that could be reached with far fewer samples.
Concrete Example:
In a long math proof, a standard reward model might assign a high score to a step that looks correct locally but actually leads to a dead end. TDRM, by propagating future value estimates backward, would lower the score of that earlier step once the dead end is realized, correcting the signal.
Key Novelty
Temporal Difference Reward Modeling (TDRM)
- Applies n-step Temporal Difference (TD) learning to train process reward models online, where the reward for a current step is updated based on the estimated value of future steps.
- Integrates a cosine-based reward shaping mechanism to stabilize training across varying chain-of-thought lengths, preventing rewards from collapsing for long reasoning traces.
- Combines these smooth process rewards with rule-based verification (outcome rewards) in a linear combination to guide Group Relative Policy Optimization (GRPO) training.
Architecture
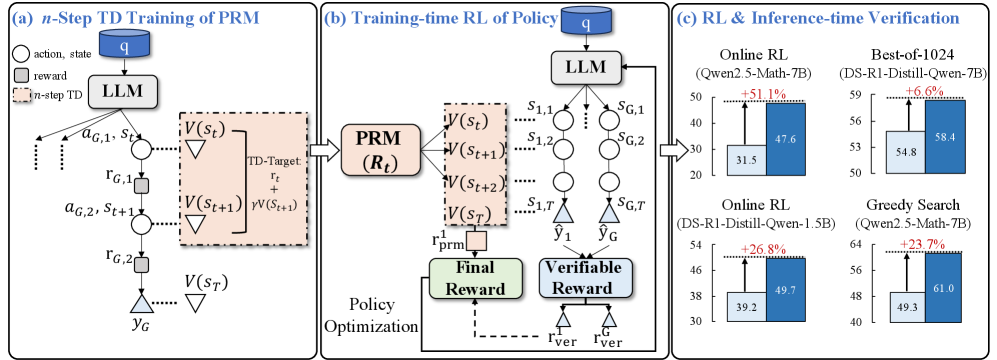
Overview of the TDRM framework, illustrating the interaction between the Policy Model, the TDRM (Process Reward Model), and the RL update loop.
Evaluation Highlights
- Achieves comparable RL performance to baselines using only 2.5k data samples, whereas baselines require 50.1k data samples (approx. 20x data efficiency gain).
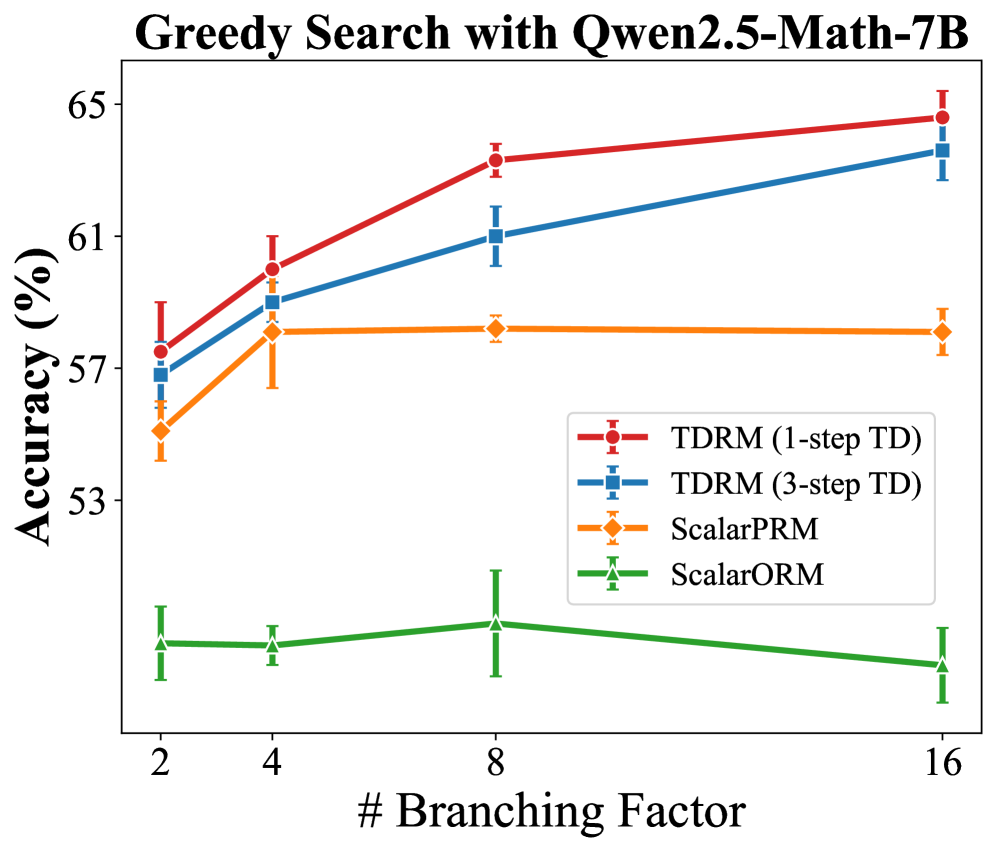
- Improves inference-time tree search accuracy by up to +23.7% compared to standard process reward models.
- Boosts Best-of-NN verification performance by up to +6.6% across various model sizes and families (e.g., Qwen2.5, GLM-4).
Breakthrough Assessment
8/10
Significant gains in data efficiency (20x) and consistent improvements across diverse models and tasks suggest a robust methodology that addresses a fundamental weakness in current reward modeling.