📊 Experiments & Results
Evaluation Setup
Mathematical reasoning tasks with deterministic verification
Benchmarks:
- AIME 2024 (Competition Math)
- AIME 2025 (Competition Math)
- MATH-500 (High-school Math)
- OlympiadBench (Competition Math)
- Omni-Math (Hard) (Competition Math (Difficulty > 7))
Metrics:
- Pass@1 Accuracy
- Statistical methodology: Logistic regression used to analyze relationship between Effective Rank and correctness (p-values reported).
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| AIME 2024 | Pass@1 | 33.3 | 56.7 | +23.4 |
| AIME 2024 | Pass@1 | 46.0 | 56.7 | +10.7 |
| MATH-500 | Pass@1 | 79.8 | 84.2 | +4.4 |
| Average (5 datasets) | Pass@1 | 44.5 | 49.8 | +5.3 |
| Average (5 datasets) | Pass@1 | 49.0 | 49.8 | +0.8 |
Experiment Figures
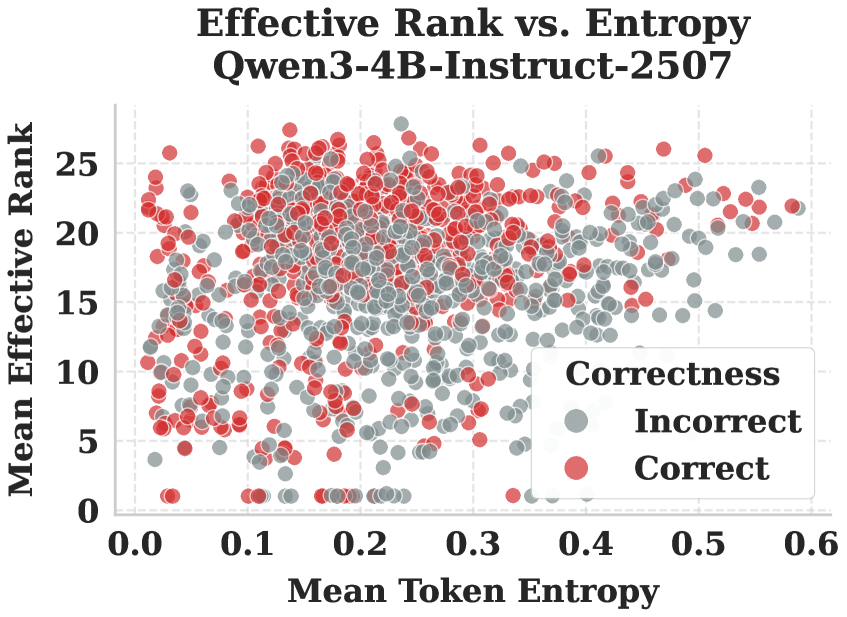
Scatter plot of Correctness vs. Entropy and Effective Rank.
Main Takeaways
- Reasoning capacity is not strictly bound by parameter count; geometric reshaping allows a 4B model to outperform a 32B model.
- Effective Rank provides a distinct signal from Entropy; high rank correlates with correctness even when controlling for uncertainty.
- The combination of Cold Start (Ejection) and Rank-Aware RL (Maintenance) is necessary; standard RL alone leads to re-collapse into the bias manifold.
- The method generalizes well across competition math benchmarks but faces some truncation issues on extremely long-context tasks (Omni-Hard).