📝 Paper Summary
GUI Agents
Reward Modeling
Reinforcement Learning with Verifiable Rewards (RLVR)
VAGEN replaces passive visual judges with an agentic verifier that actively uses tools (shell, Python, computer use) to probe the environment and verify if a GUI task was successfully completed.
Core Problem
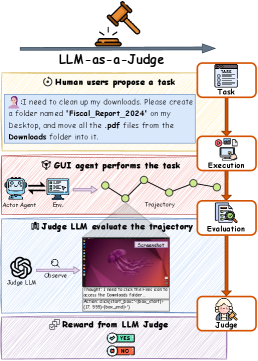
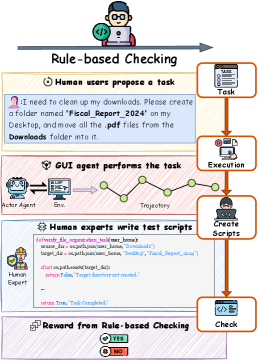
Existing evaluation methods for GUI agents either rely on unscalable manual scripts (rule-based) or passive visual observation (LLM-as-a-Judge), which fails to detect latent system states hidden from screenshots.
Why it matters:
- Partial state observability prevents passive judges from seeing critical non-visual evidence (e.g., file attributes, background processes), leading to inaccurate rewards
- Rule-based verification is brittle and cannot scale to open-ended tasks or large-scale Reinforcement Learning (RL) training
- Inaccurate reward signals hinder the optimization of GUI agents during RLVR (Reinforcement Learning with Verifiable Rewards)
Concrete Example:
For the task 'Help me buy the book Reinforcement Learning', an LLM-as-a-Judge might mistakenly approve a task based on a 'Thank You' screen, failing to verify if the correct item was actually purchased in the backend order history, which requires active clicking or probing.
Key Novelty
Verification via Agentic Environment Interaction (VAGEN)
- Empowers the reward model (verifier) with the same interactive capabilities as the actor, allowing it to actively probe the environment (e.g., open files, run shell commands) rather than just looking at screenshots
- Implements a 'Progressive Verification Mechanism' that attempts cheap static checks first, then visual retrospection, and finally active probing only when necessary
- Utilizes a 'Read-Only Scaling' strategy for test-time compute, allowing multiple verification attempts without expensive environment resets by restricting the verifier to non-destructive actions
Architecture
The overall VAGEN framework and the Progressive Verification Mechanism flow.
Evaluation Highlights
- Increases evaluation accuracy on OSWorld-Verified (Balanced) from 84.7% (LLM-as-a-Judge) to 92.9% (+8.2%)
- Improves evaluation accuracy on OSWorld-Verified (Imbalanced) from 85.3% to 93.4% (+8.1%)
- Demonstrates that verifier agents achieve higher success rates than actor agents, validating the 'easy to verify, hard to solve' property of GUI tasks
Breakthrough Assessment
8/10
Significant paradigm shift from passive observation to active probing for reward modeling. Addresses a critical bottleneck in GUI agent evaluation (partial observability) with substantial empirical gains.