📝 Paper Summary
Code Generation
Reinforcement Learning from Human Feedback (RLHF)
Reward Modeling
CodeScaler is a reward model trained on high-quality on-policy rollouts that enables scalable reinforcement learning and fast test-time scaling for code generation without requiring test case execution.
Core Problem
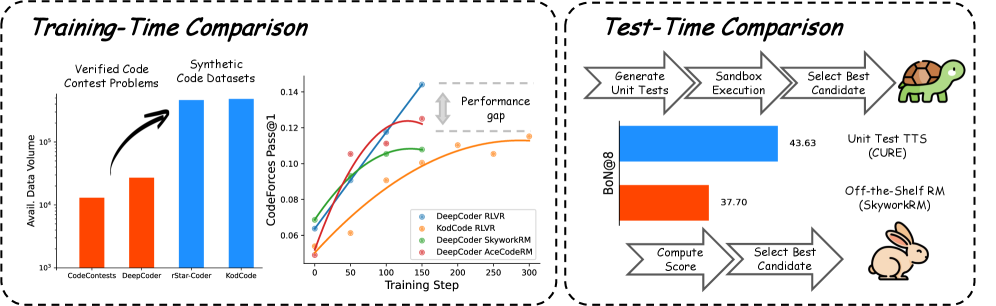
Reinforcement Learning from Verifiable Rewards (RLVR) relies on high-quality problems with curated test cases, which are scarce and costly; synthetic alternatives lack oracle solutions for reliable verification.
Why it matters:
- High-quality verified code problems are limited in scale, bottling the potential of execution-based RL.
- Existing general-purpose reward models (RMs) fail to distinguish subtle code correctness issues, leading to reward hacking and instability during RL.
- Unit-test based test-time scaling methods have high latency due to the need for code execution.
Concrete Example:
Training on the larger synthetic KodCode dataset (447K problems) yields worse performance (11.51 avg) than the smaller verified DeepCoder dataset (14.41 avg) because synthetic test cases miss corner cases, allowing incorrect solutions to pass.
Key Novelty
Syntax-Aware, Validity-Preserving Code Reward Model
- Trains a reward model on preference data derived from on-policy rollouts of an RLVR-trained model, ensuring diversity and relevance.
- Implements syntax-aware code extraction to filter invalid code before scoring, preventing the model from rewarding gibberish.
- Applies a validity-preserving reward shaping function that maps scores to a positive range and penalizes extraction failures, ensuring a stable optimization landscape.
Architecture
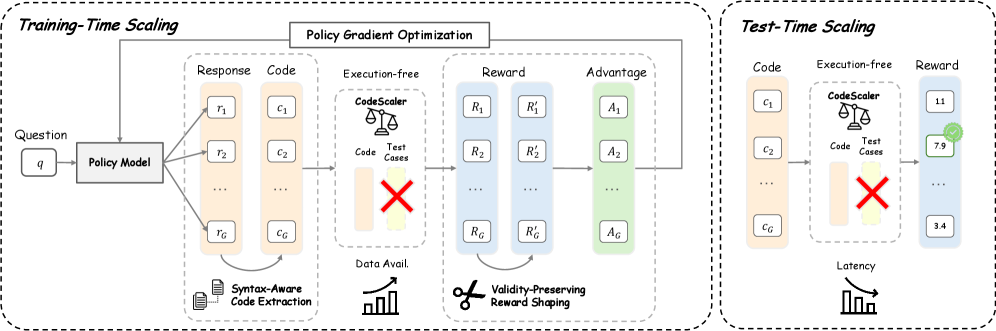
Overview of CodeScaler training and application pipeline. Left: Preference data construction from on-policy rollouts. Middle: RM training. Right: Application in RL (with validity-preserving shaping) and Inference (Best-of-N).
Evaluation Highlights
- +11.72 points average improvement for Qwen3-8B-Base across five coding benchmarks compared to the base model.
- Outperforms binary execution-based RLVR by +1.82 points on average when trained on the high-quality DeepCoder dataset.
- Achieves 10x speedup in test-time scaling compared to unit-test based methods (CURE) while maintaining comparable accuracy on CodeForces.
Breakthrough Assessment
8/10
Significantly improves code RL without execution, effectively addressing the data scarcity bottleneck of RLVR. The 10x inference speedup for test-time scaling is highly practical.