📝 Paper Summary
Unified Multimodal Models (UMMs)
Prompt Optimization / Reprompting
Visual Generation Alignment
SEER bridges the cognitive gap in unified multimodal models by turning their latent understanding into an active reasoning step that rewrites user prompts to align with the generator's internal priors.
Core Problem
Unified Multimodal Models (UMMs) understand visual instructions well but fail to follow them during image generation because they lack a mechanism to translate high-level understanding into generator-friendly descriptions.
Why it matters:
- Despite sharing architectures, current models exhibit a 'cognitive gap': they can critique an image perfectly but cannot generate it correctly
- Prior reprompting methods use disjoint models (e.g., GPT-4 rewriter + Stable Diffusion), causing 'representation mismatch' where rewrites are linguistically valid but visually unrealizable by the specific generator
- Standard RLHF for vision optimizes pixels directly, which fails to teach the model *how* to reason about the generation process itself
Concrete Example:
Given the instruction 'Make the object look scary, yet undeniably cute', a standard model might generate a generic scary object. SEER reasoning explicitly translates this into concrete descriptors like 'big eyes, fluffy texture, sharp teeth' that the specific generator knows how to render.
Key Novelty
Endogenous Reprompting via Self-Evolving Evaluator and Reprompter (SEER)
- Transforms the model's passive understanding into an active 'reprompting' step within the *same* shared parameter space, ensuring the generated prompt aligns with what the generator can actually draw
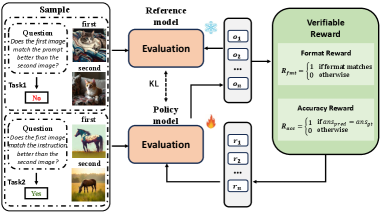
- Uses a two-stage loop: first training the model to be a verifiable evaluator (RLVR), then using that evaluator to train the model to think and rewrite prompts (RLMT), all using only 300 seed samples
Architecture
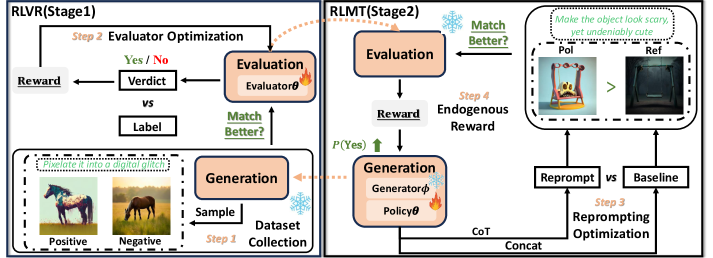
The SEER framework workflow. It shows the transition from a passive UMM to an active reasoning agent.
Evaluation Highlights
- Outperforms state-of-the-art baselines like Emu3 and Janus-Pro in instruction adherence and visual quality.
- Achieves self-evolution using only 300 samples from a compact proxy task, compared to thousands used in standard fine-tuning.
- Demonstrates that optimizing the reasoning (prompt) is more effective than optimizing the execution (pixels) for unlocking latent generative capabilities.
Breakthrough Assessment
8/10
Innovative use of 'endogenous' feedback loops (using the model to teach itself) to solve the alignment problem without massive external supervision or disjoint models. The low data requirement (300 samples) is particularly striking.