📝 Paper Summary
LLM Evaluation
Reinforcement Learning with Verifiable Rewards (RLVR)
Post-training / Alignment
RubricHub automates the creation of fine-grained evaluation rubrics using a coarse-to-fine generation pipeline, enabling post-training strategies that allow smaller models to outperform proprietary frontiers on open-ended tasks.
Core Problem
Open-ended generation lacks ground truth for verification, while existing rubric-based methods suffer from low discriminability (coarse criteria) and limited scalability due to reliance on manual expertise.
Why it matters:
- Current rubrics often fail to distinguish between 'excellent' and 'exceptional' responses, creating a supervision ceiling effect for top-tier models
- Manual rubric creation is expensive and hard to scale across diverse domains like medical or creative writing
- Lack of fine-grained supervision prevents effective Reinforcement Learning (RL) in non-math/code domains where answers are subjective
Concrete Example:
A standard rubric might simply ask 'Is the code correct?', failing to differentiate a basic O(n^2) solution from an optimized O(n) solution that handles edge cases. This lack of nuance prevents the model from learning to produce the optimized version.
Key Novelty
Automated Coarse-to-Fine Rubric Generation Framework
- Synthesizes criteria using response-grounding (anchoring to actual outputs) and principle-guidance (enforcing meta-principles like clarity) to prevent hallucinated or generic rules
- Aggregates perspectives from multiple heterogeneous models to remove single-source bias, then evolves criteria to be 'harder' by analyzing differences between high-quality responses
- Constructs a massive dataset (~110k rubrics) that is dense (30+ criteria per query) and highly discriminative, enabling robust Rejection Sampling and RL
Architecture
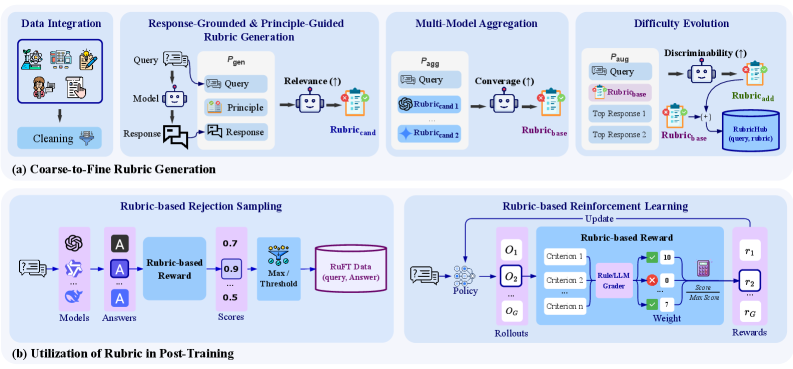
The automated Coarse-to-Fine Rubric Generation framework pipeline.
Evaluation Highlights
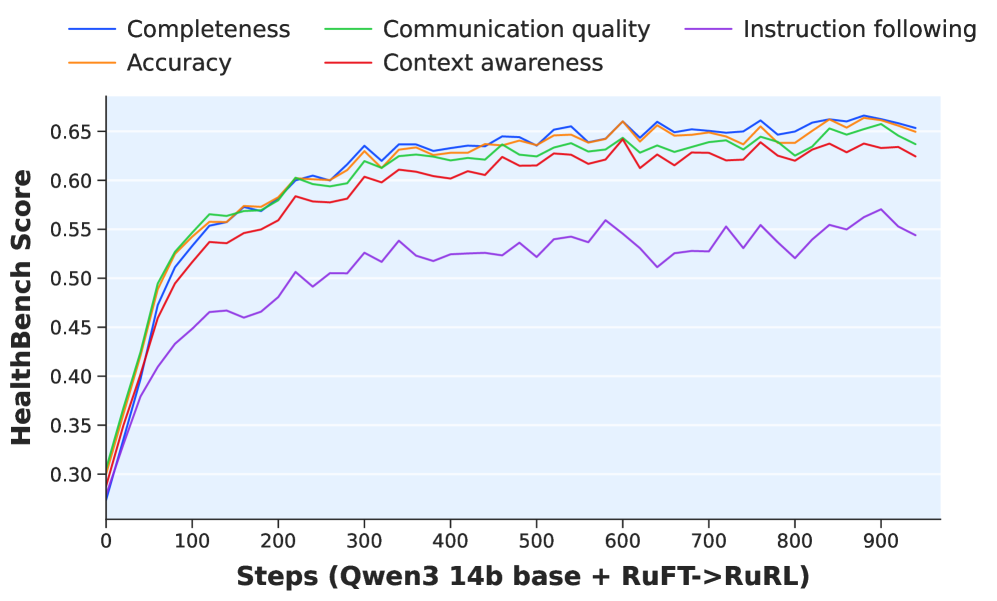
- Qwen3-14B post-trained with RubricHub achieves 69.3 on HealthBench, achieving SOTA and surpassing GPT-5 (67.2)
- On ArenaHard V2, Qwen3-14B score improves from 5.2 (Base) to 74.4 after full RuFT + RuRL pipeline
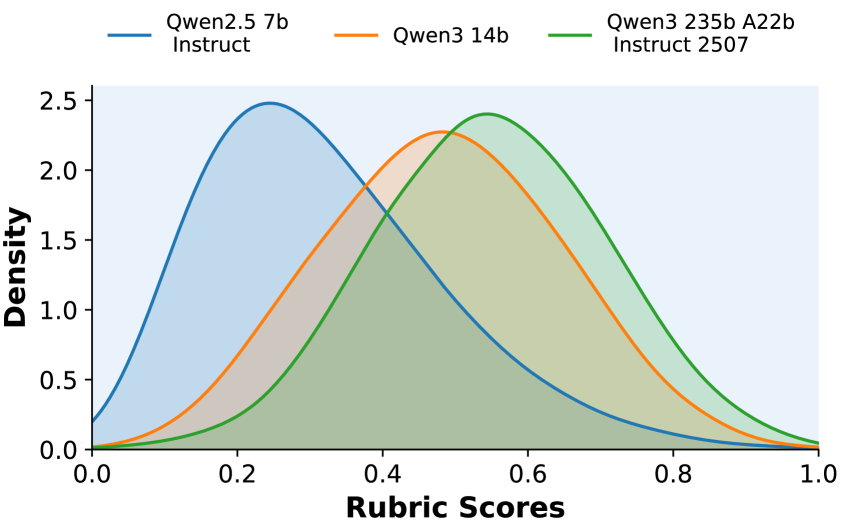
- RubricHub-generated rubrics improve HealthBench supervision quality significantly over RaR rubrics (62.1 vs 47.7)
Breakthrough Assessment
9/10
Significant methodology for converting open-ended tasks into verifiable RL problems. The empirical results (beating GPT-5 with a 14B model) are striking and demonstrate the power of high-quality, dense supervision signals.