📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
LLM Post-training
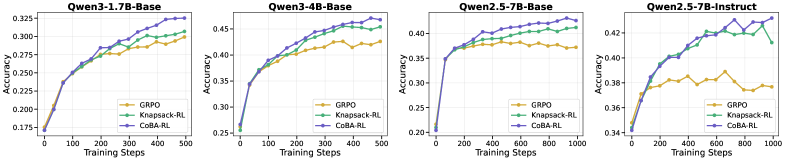
CoBA-RL optimizes reinforcement learning efficiency by dynamically allocating rollout budgets to tasks based on the model's real-time failure rate, prioritizing consolidation of easy tasks before exploring harder ones.
Core Problem
Standard RL frameworks like GRPO use uniform rollout budgets for all prompts regardless of difficulty, while static adaptive methods fail to account for the model's changing capabilities during training.
Why it matters:
- Uniform allocation wastes computational resources on samples that are either too easy (already mastered) or too hard (impossible), reducing training efficiency.
- Static difficulty metrics (like historical pass rates) incorrectly assume a task's training value is constant, ignoring that 'difficulty' is relative to the model's current skill level.
- Effective reasoning requires balancing exploitation (mastering known tasks) and exploration (finding solutions for hard tasks), which shifts as the model learns.
Concrete Example:
In a math training batch, a uniform strategy generates 16 solutions for both a simple '2+2' query and a complex Olympiad problem. The model wastes resources generating 16 correct '2+2' answers (zero marginal gain) while failing to solve the Olympiad problem because 16 attempts were insufficient to find a correct path.
Key Novelty
Capability-Oriented Budget Allocation (CoBA-RL)
- Quantifies the 'training value' of each task using a Beta distribution that changes shape based on the model's real-time global failure rate.
- Implements an 'Exploit → Explore' strategy: early training prioritizes easy tasks to consolidate basics, while later training shifts resources to harder tasks for exploration.
- Uses a heap-based greedy algorithm to efficiently solve the budget allocation problem, maximizing total batch value under a fixed compute budget.
Architecture
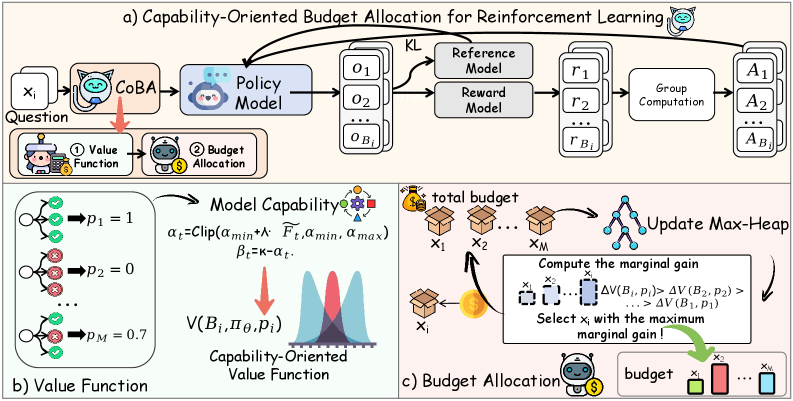
The CoBA-RL training workflow, detailing how global failure rates inform the value function which then guides budget allocation.
Evaluation Highlights
- +5.62% accuracy improvement on AIME25 with Qwen2.5-7B-Instruct compared to the GRPO baseline.
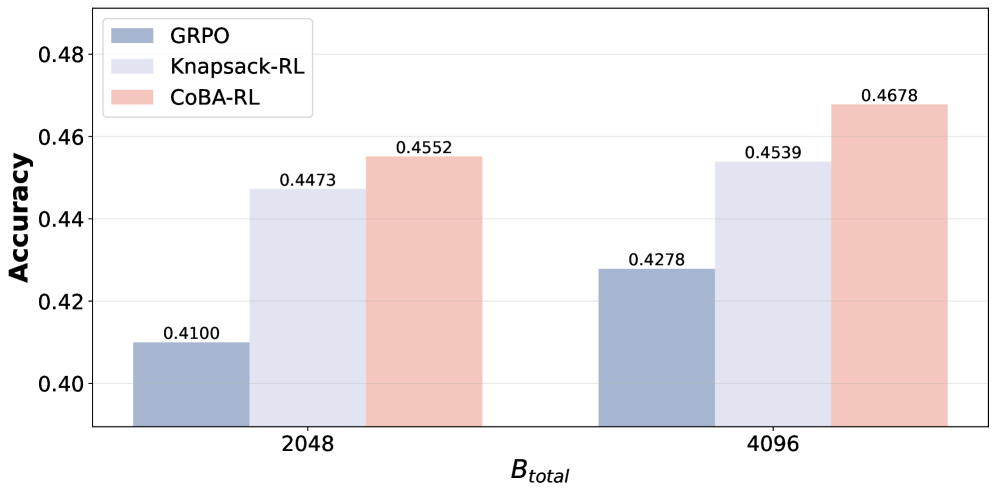
- Achieves higher accuracy (45.52%) with half the budget (2048 rollouts) than GRPO achieves with full budget (4096 rollouts, 42.78%), demonstrating superior data efficiency.
- Outperforms static heuristic strategies (Linear Step Decay) and static value functions across multiple math benchmarks.
Breakthrough Assessment
8/10
Significant efficiency gains and strong empirical results on challenging math benchmarks. The dynamic 'Exploit -> Explore' mechanism challenges the conventional uniform or static-difficulty paradigms in RLVR.