📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Mathematical Reasoning
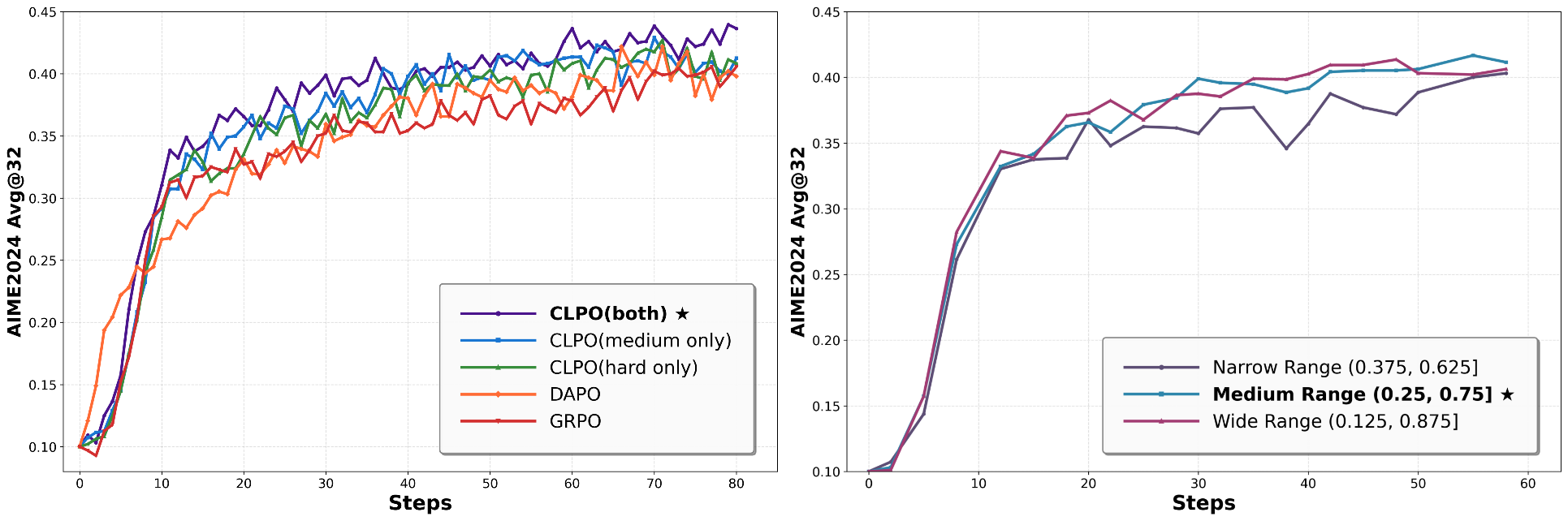
CLPO improves LLM reasoning by using the model's own rollout performance to dynamically build a curriculum, simplifying hard problems and diversifying medium ones for targeted self-improvement.
Core Problem
Standard RLVR methods sample training data uniformly, ignoring that models have already mastered some problems while finding others intractable, leading to inefficient exploration and limited learning.
Why it matters:
- Uniform sampling wastes compute on easy problems the model has already mastered
- The model struggles to learn from hard problems that are far beyond its current capabilities without guidance
- Existing solutions often rely on expensive external teachers (e.g., GPT-4o) or static datasets, lacking efficient endogenous self-evolution
Concrete Example:
A model might repeatedly solve 2+2 correctly (zero learning gain) while failing to solve a complex calculus problem (zero reward signal). Without intervention, it cannot bridge the gap to the hard problem or move on from the easy one.
Key Novelty
Curriculum-guided Learning for Policy Optimization (CLPO)
- Treats the RL rollout phase as a diagnostic tool to measure problem difficulty in real-time based on the model's own success rate
- Uses this difficulty signal to act as its own teacher: it simplifies hard problems to make them learnable and diversifies medium problems to boost generalization
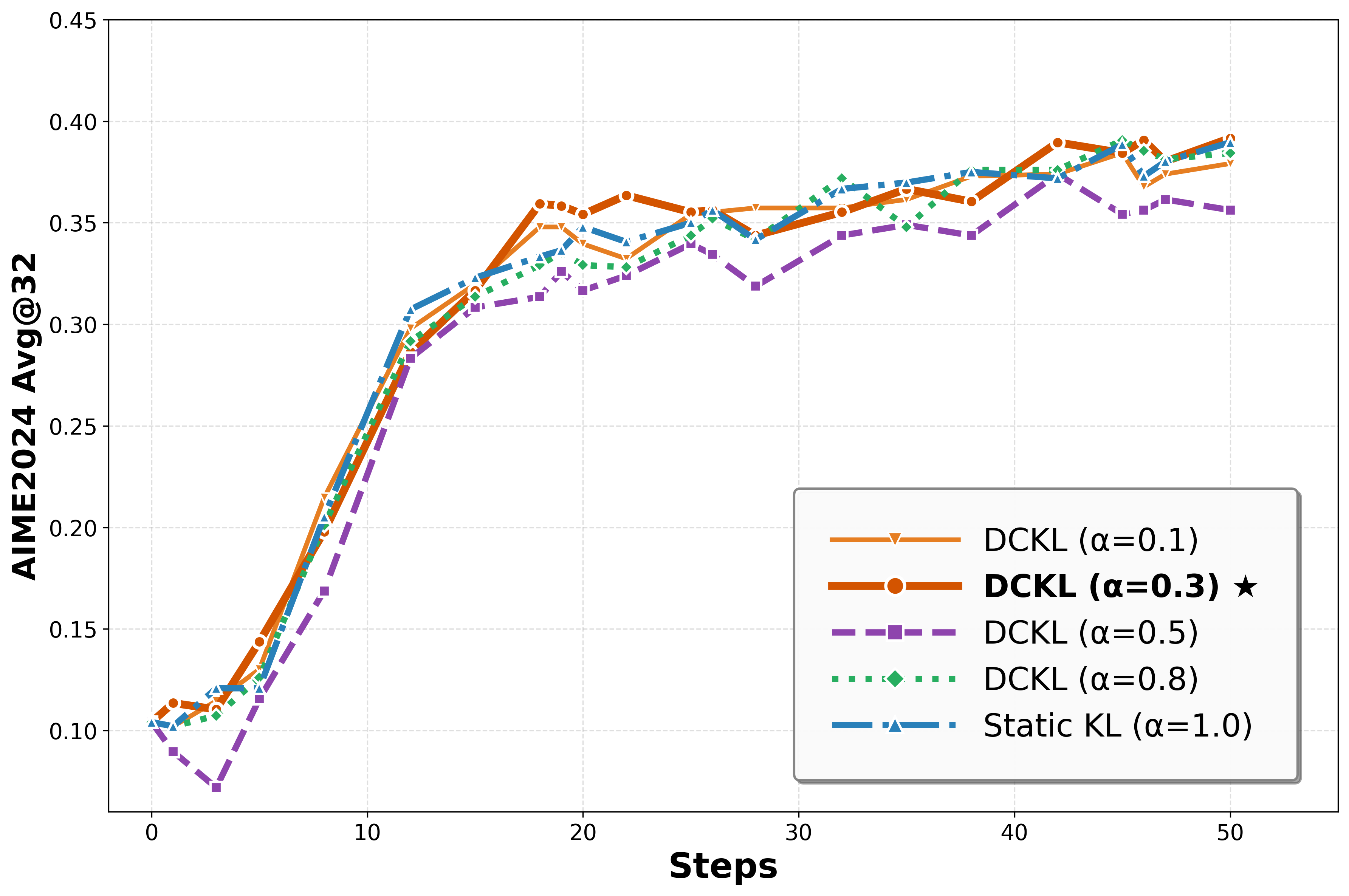
- Adjusts the optimization objective dynamically, applying weaker constraints (lower KL penalty) on hard problems to encourage more aggressive exploration
Architecture
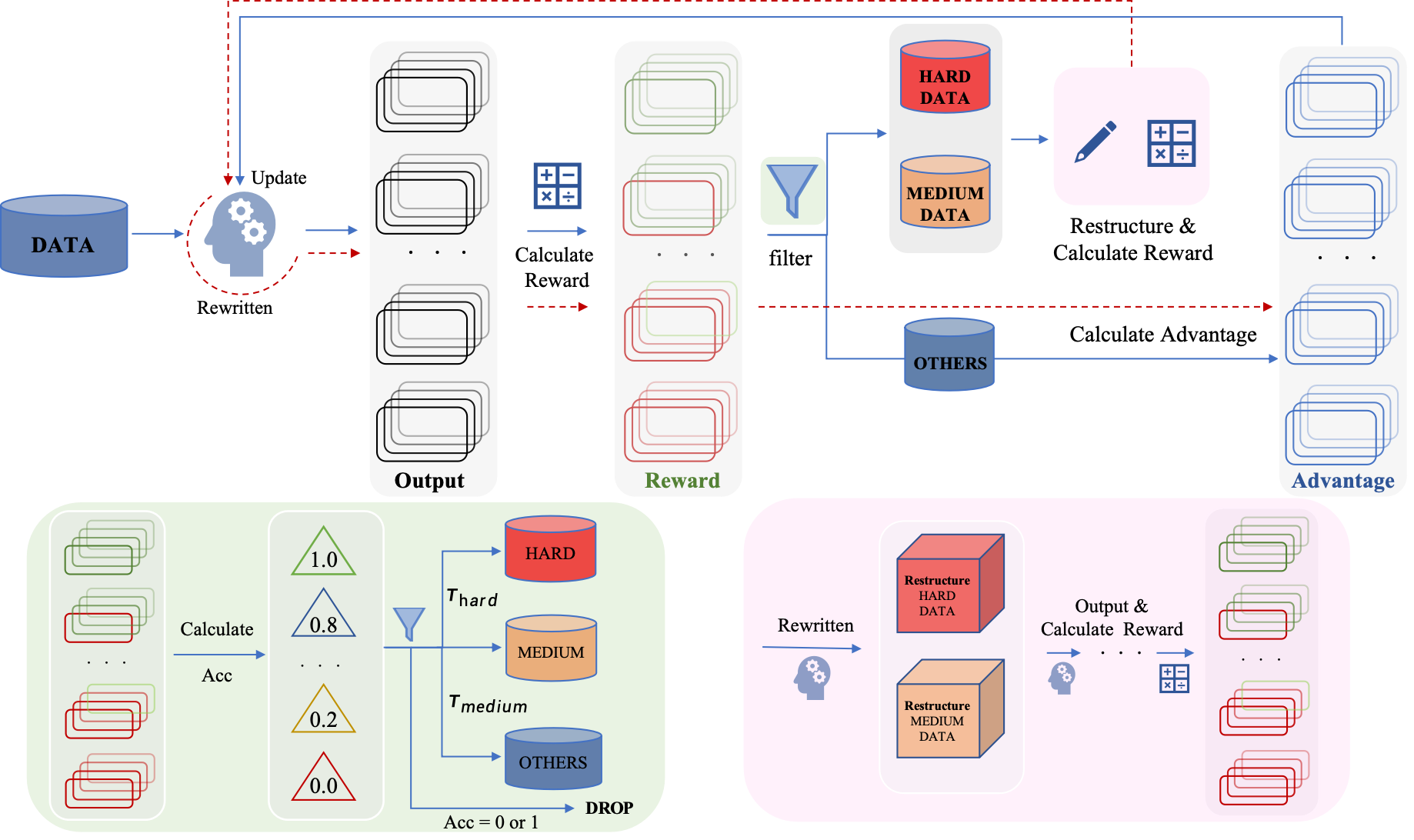
The CLPO framework workflow: Rollout -> Difficulty Assessment -> Adaptive Restructuring -> Policy Optimization.
Evaluation Highlights
- Achieves +6.96% average pass@1 improvement over baselines across 8 benchmarks using Qwen3-8B
- Sets new SOTA pass@1 on the challenging AIME 2024 benchmark, outperforming strong baselines by 3.3%
- Outperforms Critique-GRPO (which uses GPT-4o feedback) on multiple datasets without needing any external teacher
Breakthrough Assessment
8/10
Strong methodological contribution effectively integrating curriculum learning into RLVR loops. Demonstrates significant gains on hard benchmarks without external dependencies, addressing a key efficiency bottleneck in self-play.