📝 Paper Summary
Multimodal Reinforcement Learning
Vision-Language Model Reasoning
VPPO improves multimodal reasoning by quantifying visual dependency at the token level to strictly reward only the specific tokens and trajectories that genuinely rely on visual data.
Core Problem
Standard Reinforcement Learning with Verifiable Rewards (RLVR) broadcasts a uniform reward to all tokens in a correct response, ignoring that many tokens (like connective text) require no visual perception.
Why it matters:
- Rewarding non-visual tokens dilutes the learning signal, preventing the model from learning distinct multimodal connections
- Models may learn shortcuts (e.g., guessing based on text priors) rather than genuine visually-grounded reasoning, as all correct outcomes are rewarded equally
- Current methods lack mechanisms to distinguish between perception-driven reasoning paths and fortuitous guesses
Concrete Example:
In a geometry problem asking for an angle in a circle, a model might correctly guess the answer using text rules without realizing that two segments are radii (a visual constraint). Standard RL rewards this lucky guess equally to a reasoned path, reinforcing the blind shortcut.
Key Novelty
Visually-Perceptive Policy Optimization (VPPO)
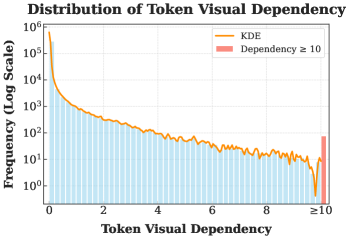
- Quantifies 'Token Perception' by measuring the KL divergence between the policy's output given the image versus a perturbed (non-informative) image
- Applies a 'Gradient Mask' to focus policy updates exclusively on the top-k% of tokens with high visual dependency, filtering out noise from generic text tokens
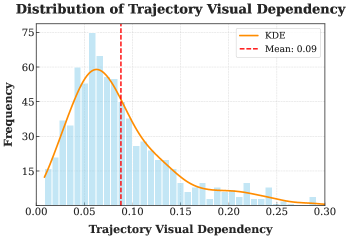
- Reweights trajectory advantages based on their average visual dependency, prioritizing reasoning paths that actively use the image over those that ignore it
Architecture
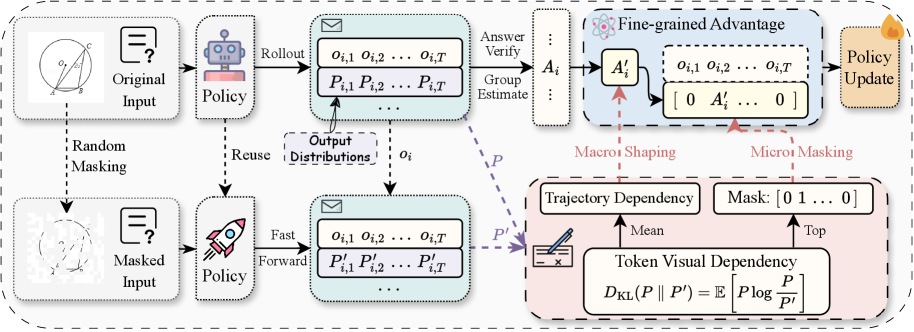
The VPPO training pipeline showing how token visual dependency is calculated and used to modulate the optimization.
Evaluation Highlights
- +19.2% average accuracy improvement with Qwen2.5-VL-7B across eight multimodal reasoning benchmarks compared to the baseline
- +7.6% average accuracy improvement with Qwen2.5-VL-32B, demonstrating scalability to larger models
- Achieves superior training stability and faster convergence by reducing gradient variance via token-level masking
Breakthrough Assessment
8/10
Introduces a fundamental metric (visual dependency) to multimodal RL, moving beyond coarse outcome-based rewards. The significant gains (+19.2%) on established baselines suggest a highly effective optimization strategy.