📝 Paper Summary
Large Language Model Reasoning
Reinforcement Learning with Verifiable Rewards (RLVR)
UloRL enables efficient reinforcement learning for ultra-long reasoning chains by dividing generation into segments to reduce wait times and dynamically masking mastered tokens to prevent entropy collapse.
Core Problem
Traditional RL frameworks are inefficient for ultra-long outputs (e.g., 128k tokens) due to long-tail decoding delays, and suffer from entropy collapse where models prematurely lose diversity.
Why it matters:
- Increasing output length significantly enhances reasoning capabilities, as seen in models like OpenAI o1 and DeepSeek R1.
- Waiting for the longest sample in a batch to finish decoding creates massive idle time for computational resources.
- Existing methods to fix entropy collapse often hurt performance by adding conflicting loss terms or indiscriminately clipping updates.
Concrete Example:
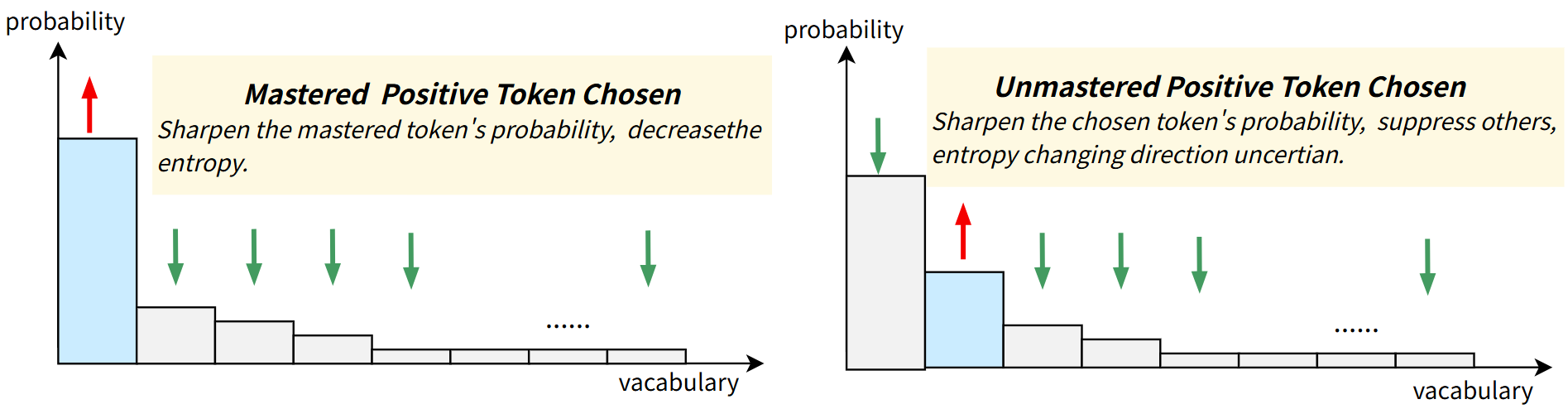
In a batch where 80% of samples finish within 64k tokens, the entire training process must wait for a single 128k-token sample to complete, wasting GPU resources. Furthermore, standard RL causes the model to overtrain on easy tokens (like 'the' or simple steps), sharpening the distribution until diversity vanishes.
Key Novelty
Segment Rollout with Pseudo On-Policy Importance Sampling and Dynamic Token Masking
- Splits ultra-long decoding into small chunks (segments); completed segments are trained immediately while unfinished ones continue, eliminating long-tail idle time.
- Treats the most recent segment as 'on-policy' data (weight=1) to stabilize training, avoiding the instability of off-policy clipping.
- Dynamically masks 'well-mastered' tokens (those predicted with high confidence) from the loss function only when entropy drops too low, preserving diversity without hurting learning.
Architecture
Comparison of standard RL rollout vs. Segment Rollout and the corresponding Importance Sampling strategies.
Evaluation Highlights
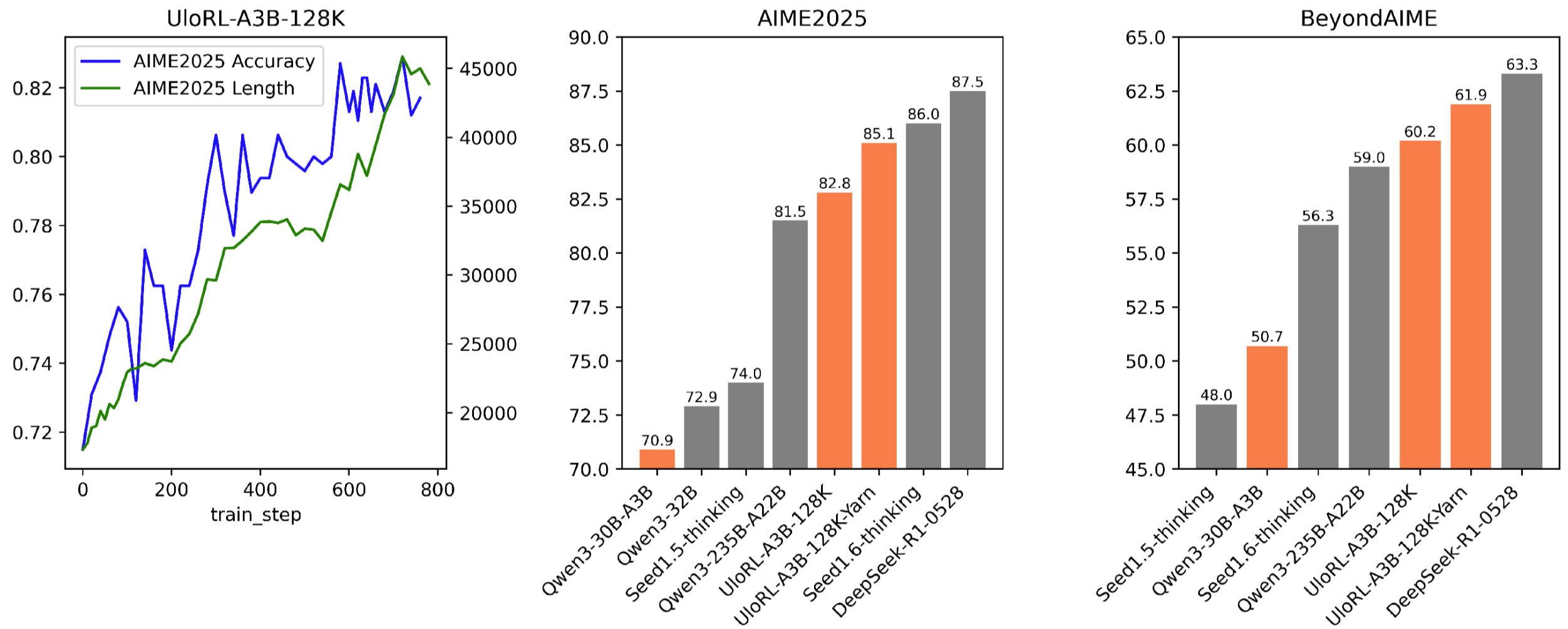
- 2.06x faster training speed on Qwen3-30B-A3B with 4-segment rollout compared to standard full rollout.
- +14.2% accuracy improvement on AIME2025 (70.9% → 85.1%) using 128k-token outputs.
- Surpasses the much larger Qwen3-235B-A22B model on AIME2025 (85.1% vs 81.5%) despite being ~8x smaller.
Breakthrough Assessment
8/10
Significant engineering breakthrough in making ultra-long chain-of-thought training practical. The segment rollout addresses a critical efficiency bottleneck, and the dynamic masking offers a principled fix for entropy collapse.