📝 Paper Summary
Reinforcement Learning for Reasoning
Post-training of Large Language Models
Nemotron-Cascade achieves state-of-the-art reasoning by applying reinforcement learning sequentially across domains (alignment, math, code) rather than jointly, preventing catastrophic forgetting while enabling specialized verification strategies.
Core Problem
Training general-purpose reasoning models is difficult because different domains (e.g., math vs. creative writing) require heterogeneous reward signals and verification latencies, complicating RL infrastructure and curriculum.
Why it matters:
- Current approaches that blend all prompts together for joint training suffer from slow training cycles due to the slowest verification tasks (e.g., code execution)
- Unified models often show degraded performance in 'thinking' mode compared to dedicated reasoning models, creating a trade-off between versatility and peak reasoning power
- Heterogeneous prompt distributions make hyperparameter selection and curriculum design (e.g., response length extension) challenging for a single monolithic training run
Concrete Example:
When training jointly, fast symbolic math verification must wait for slow code-execution verification within the same batch. Furthermore, alignment RLHF is often skipped or deprioritized, leading to verbose or poorly formatted responses that degrade reasoning accuracy.
Key Novelty
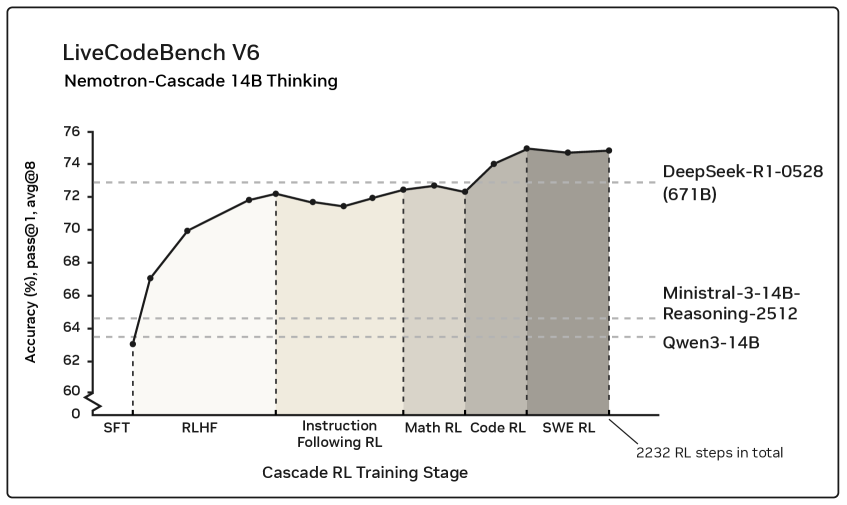
Cascaded Domain-wise Reinforcement Learning (Cascade RL)
- Orchestrates RL training sequentially by domain (Alignment → Math → Code → SWE) rather than mixing all data, allowing domain-specific hyperparameters and immediate updates for fast-verification domains
- Demonstrates that RLHF (alignment) as a pre-step significantly boosts reasoning by improving response structure, and that subsequent RL stages do not cause catastrophic forgetting of previous skills
Architecture
Overview of the Nemotron-Cascade training pipeline, illustrating the sequential progression through different training stages.
Evaluation Highlights
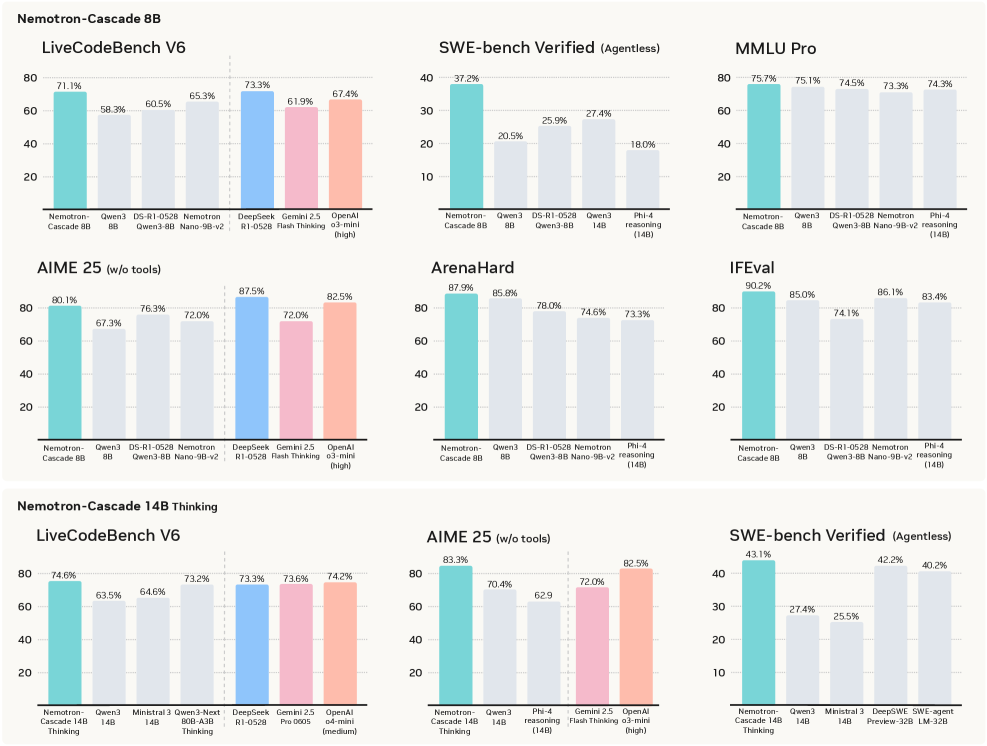
- Nemotron-Cascade-14B-Thinking achieves 77.5% pass@1 on LiveCodeBench v5, outperforming its teacher model DeepSeek-R1-0528 (671B) which scores 74.8%
- The 8B Unified model achieves 90.2% on IFEval (Strict), improving +5.2 points over the Qwen3-8B base, showing that reasoning models can retain strong instruction-following capabilities
- Achieved Silver-medal performance in the 2025 International Olympiad in Informatics (IOI) with the 14B model
Breakthrough Assessment
9/10
Successfully scales a sequential RL paradigm that beats teacher models 40x its size on coding benchmarks. The unified model approach elegantly solves the 'thinking vs. instruct' trade-off.