📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Self-Verification in LLMs
RISE trains language models to simultaneously solve problems and verify their own solutions within a single online reinforcement learning loop using verifiable rewards for both tasks.
Core Problem
Even with outcome-based reinforcement learning, models suffer from 'superficial self-reflection,' where they learn to generate correct answers without developing the ability to robustly verify or critique their own reasoning.
Why it matters:
- Models may stumble upon correct answers without true understanding, leading to brittleness.
- Current approaches decouple problem-solving training from verification training, preventing the model from learning to self-correct effectively during the reasoning process.
- Reliable self-verification is essential for deploying LLMs in high-stakes domains like mathematics and coding where correctness is paramount.
Concrete Example:
A model might output a correct final answer for a math problem but use flawed logic in the steps. Without explicit verification training, it cannot detect these internal inconsistencies. Conversely, a standard RL model might solve a problem correctly but, when asked to verify it, hallucinate a critique saying the correct answer is wrong.
Key Novelty
RISE (Reinforcing Reasoning with Self-Verification)
- Integrates self-verification directly into the online RL loop: for every batch of generated solutions, the model immediately generates verification critiques for those same solutions.
- Uses the same rule-based outcome verifier (ground truth) to reward both the problem-solving accuracy and the verification accuracy (whether the model's critique score matches the actual correctness).
- Updates the policy using a combined trajectory of reasoning and verifying, forcing the model to align its generation capabilities with its assessment capabilities.
Architecture
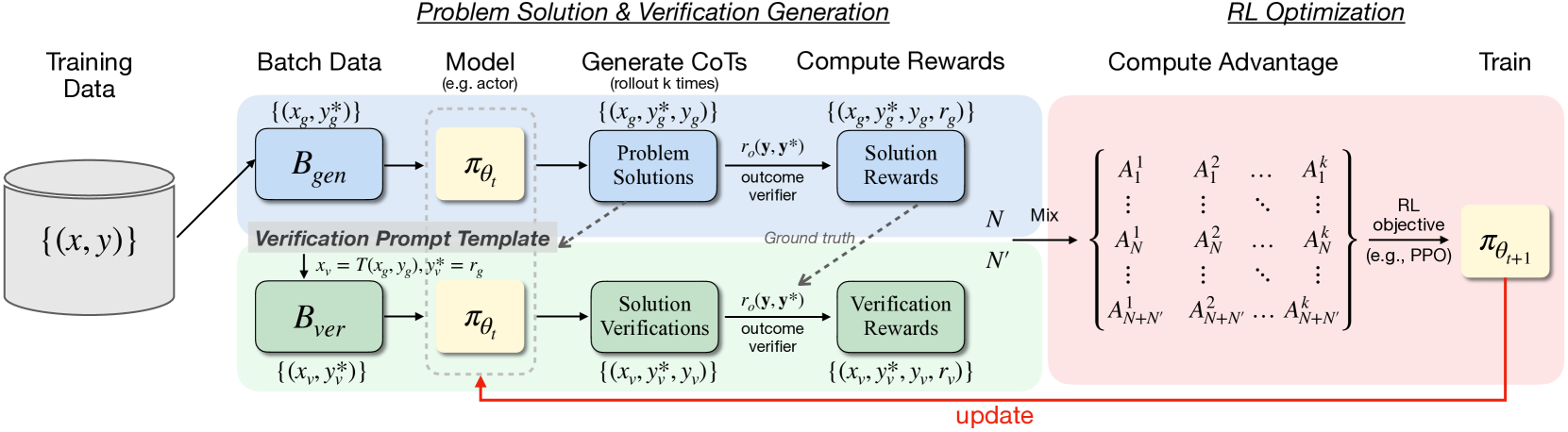
The RISE framework's online reinforcement learning loop.
Evaluation Highlights
- RISE-3B achieves a 3.7% average improvement in reasoning accuracy over Qwen-3B-Instruct on mathematical benchmarks.
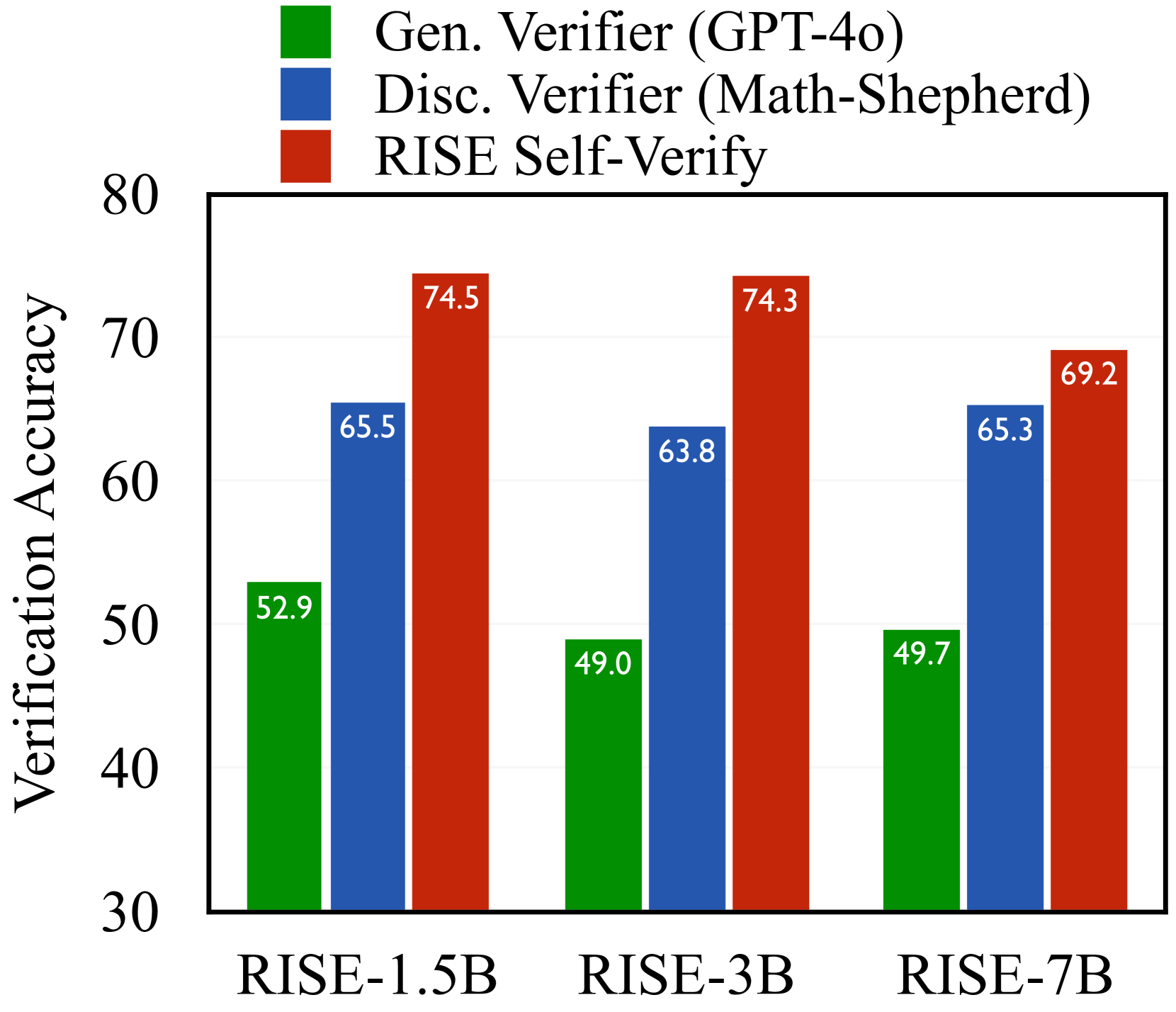
- RISE achieves up to a 2.8x increase in verification accuracy compared to a Zero-RL baseline.
- At test time, RISE-7B outperforms standard majority voting by +1.9% under a k=4 inference budget.
Breakthrough Assessment
8/10
Strong conceptual advance by unifying generation and verification in a single online RL process. Significant empirical gains in verification reliability without sacrificing reasoning performance.